Chapter 2: Cryptography#
“Cryptography is the essential building block of independence for organizations on the Internet, just like armies are the essential building blocks of states.” – Julian Assange, paraphrasing a common sentiment in the cypherpunk movement
Learning Objectives#
After completing this chapter, you will be able to:
Define the goals of cryptography (confidentiality, integrity, authentication, non-repudiation) and state Kerckhoffs’s principle.
Break classical ciphers using frequency analysis and explain why they fail.
Explain perfect secrecy and the one-time pad, and why perfect secrecy is impractical at scale.
Distinguish true randomness, pseudo-randomness, and cryptographically secure pseudo-randomness, and identify the danger of weak generators.
Describe symmetric encryption, contrast stream and block ciphers, and explain the AES structure.
Compare the block-cipher modes of operation (ECB, CBC, CFB, OFB, CTR, GCM) and justify why ECB is insecure.
Explain cryptographic hash functions, their security properties, and constructions such as Merkle-Damgard and Merkle trees.
Explain message authentication codes (HMAC), authenticated encryption (AEAD), key derivation functions, and secure password storage.
Describe public-key cryptography: RSA, Diffie-Hellman key exchange, and elliptic-curve cryptography.
Explain digital signatures, public-key infrastructure, certificates, and the TLS handshake.
Describe advanced and forward-looking topics: homomorphic encryption, functional encryption, oblivious computation, steganography, and post-quantum cryptography.
Key Terms#
Plaintext / ciphertext: the readable message and its encrypted form.
Cipher: an algorithm for encryption and decryption.
Key: the secret parameter that controls a cipher’s output.
Symmetric cryptography: encryption and decryption use the same shared secret key.
Asymmetric (public-key) cryptography: a mathematically linked key pair, public and private.
Kerckhoffs’s principle: a cryptosystem must be secure even if everything except the key is public.
Cryptanalysis: the study of breaking cryptographic systems.
Hash function: a one-way function mapping arbitrary input to a fixed-size digest.
MAC: message authentication code, a keyed tag proving integrity and authenticity.
AEAD: authenticated encryption with associated data; confidentiality plus integrity in one step.
KDF: key derivation function, deriving keys from passwords or other key material.
Perfect secrecy: a ciphertext reveals nothing about the plaintext, even to an unbounded adversary; achieved by the one-time pad.
XOR (exclusive-or): the bitwise operation underlying the one-time pad and stream ciphers; its own inverse.
One-time pad (OTP): a perfectly secret cipher using a truly random key as long as the message, used once.
Computational security: security only against feasible (probabilistic polynomial-time) adversaries.
Advantage / negligible function: an adversary’s edge over guessing; negligible if it shrinks faster than any inverse polynomial.
Semantic security: a ciphertext reveals no partial information about the plaintext; equivalent to IND-CPA.
Ciphertext indistinguishability (IND-CPA, IND-CCA1, IND-CCA2): game-based confidentiality notions of increasing strength.
Non-malleability (NM-CPA, NM-CCA2): an attacker cannot transform a ciphertext into one with a related plaintext; NM-CCA2 equals IND-CCA2.
IND-CPA^D (IND-CPA with decryption oracle): confidentiality when honest decryptions are shared; the right target for approximate or failure-prone homomorphic encryption.
Noise flooding (smudging): adding large extra noise to a decryption to mask secret-leaking residual error, achieving IND-CPA^D.
ECDLP: elliptic-curve discrete logarithm problem, the hard problem behind ECC.
ECDH / ECDSA: elliptic-curve key exchange and digital signature algorithms.
Provable (reductionist) security: proving a scheme secure by reducing a break to solving a hard problem.
DDH / CDH: decisional and computational Diffie-Hellman hardness assumptions.
Random Oracle Model (ROM): a proof idealization treating a hash as a truly random function.
EUF-CMA / SUF-CMA: existential / strong unforgeability under chosen-message attack (signatures, MACs).
Simulation-based security / UC: security defined by indistinguishability from an ideal world; UC adds secure composition.
Dolev-Yao model: symbolic adversary that controls the network but cannot break perfect crypto.
Forward secrecy: past sessions stay safe even if a long-term key is later compromised.
Unlinkability / anonymity / non-repudiation: protocol-level privacy and accountability properties.
Feistel network / Merkle-Damgard: standard block-cipher and hash constructions.
Data at rest / in transit / in use: the three data states, protected by encryption at rest, in transit, and (via TEEs/homomorphic encryption) in execution.
Confidential computing / TEE: hardware-isolated execution (Intel SGX, AMD SEV) that keeps data encrypted in use.
Tamper-evident vs tamper-proof (tamper-resistant): mechanisms that detect tampering (MACs, audit logs) vs resist it (HSM, TPM, secure element).
KMS / envelope encryption: a centralized key-management service; encrypt data with a data key that is itself wrapped by a master key held in the KMS.
Key escrow: depositing a recoverable copy of a key with a third party; useful for recovery, controversial as government backdoor (Clipper chip).
PKI: public-key infrastructure, the system of certificate authorities and certificates that binds public keys to identities.
Note
Imagine passing a note in class. Anyone who intercepts it can read it, unless you and your friend agreed in advance on a secret way to scramble the letters. Cryptography is the mathematics of doing this so well that even someone with a supercomputer and the full description of your scrambling method, but not your secret key, cannot read the note. The rest of this chapter turns that intuition into precise, testable guarantees.
2.1 What Cryptography Is and What It Promises#
Cryptography is the science of securing communication and data in the presence of adversaries. It is the mathematical engine beneath nearly every security control in this book: it is how a website proves its identity, how a password is stored safely, how a software update is shown to be authentic, and how a messaging app keeps conversations private. The word comes from the Greek for “hidden writing,” but modern cryptography reaches far beyond secrecy. It provides four distinct services, and keeping them separate in your mind is essential.
Confidentiality ensures that only authorized parties can read a message; this is encryption in the everyday sense. Integrity ensures that a message has not been altered, so the recipient can detect tampering. Authentication ensures that a message genuinely comes from its claimed sender. Non-repudiation ensures that a sender cannot later deny having sent a message, a stronger property that requires public-key signatures. A single protocol often combines several of these; for example, when you log in to a bank, TLS provides confidentiality and integrity for the connection and authenticates the server to you.
A foundational rule governs all serious cryptography: Kerckhoffs’s principle, which states that a cryptosystem should remain secure even if everything about the system, except the secret key, is public knowledge. The modern restatement, attributed to Claude Shannon, is to assume “the enemy knows the system.” This is why reputable cryptographic algorithms are published, standardized, and subjected to years of public analysis rather than kept secret. Security that depends on hiding the algorithm, disparagingly called security through obscurity, fails the moment the algorithm leaks or is reverse engineered, and history is littered with such failures. When you design or select cryptography, trust only algorithms that have survived sustained public scrutiny, and never invent your own cipher for production use.
It is equally important to know cryptography’s limits. Encryption protects data, not the endpoints: if an attacker controls your device, the strongest cipher will not save you, because the plaintext is right there. Cryptography also cannot fix a bad protocol around it, cannot compensate for a weak or leaked key, and is frequently undone not by breaking the mathematics but by implementation mistakes: predictable randomness, reused keys, timing side channels, and downgrade attacks. Throughout this chapter, watch how often the system fails even when the algorithm is sound.
Encoding versus Encryption versus Hashing#
Three operations are constantly confused, even by practitioners, yet they serve entirely different purposes, and conflating them causes real security failures (for example, treating Base64 encoding as if it protected data). The distinction turns on two questions: is the transformation reversible, and does it depend on a secret key?
Encoding transforms data into another format using a public, keyless, reversible scheme, purely for compatibility or transport, not secrecy. ASCII, Unicode, Base64, and URL-encoding are encodings: anyone who knows the (public) scheme can decode the data instantly, so encoding provides no confidentiality whatsoever. Encryption transforms data into ciphertext using an algorithm and a secret key; it is reversible only by someone holding the right key, and its purpose is confidentiality. Hashing applies a one-way function to produce a fixed-size digest; it is deliberately not reversible and uses no key (in its plain form), and its purpose is integrity and identification, not secrecy. The table and figure below make the contrast precise.
Property |
Encoding |
Encryption |
Hashing |
|---|---|---|---|
Purpose |
Usability / transport |
Confidentiality |
Integrity / verification |
Uses a key? |
No |
Yes (secret) |
No (plain) / key for MAC |
Reversible? |
Yes (public scheme) |
Yes (with key) |
No (one-way) |
Output size |
Varies with input |
Varies with input |
Fixed (e.g., 256 bits) |
Examples |
ASCII, Base64, URL-encode |
AES, RSA, ChaCha20 |
SHA-256, SHA-3, BLAKE2 |
Security provided |
None |
Confidentiality |
Integrity (not secrecy) |
The single most important takeaway is that encoding is not encryption: Base64-encoding a password hides nothing, because anyone can decode it. Use encoding for compatibility, encryption for secrecy, and hashing for integrity, and never substitute one for another.
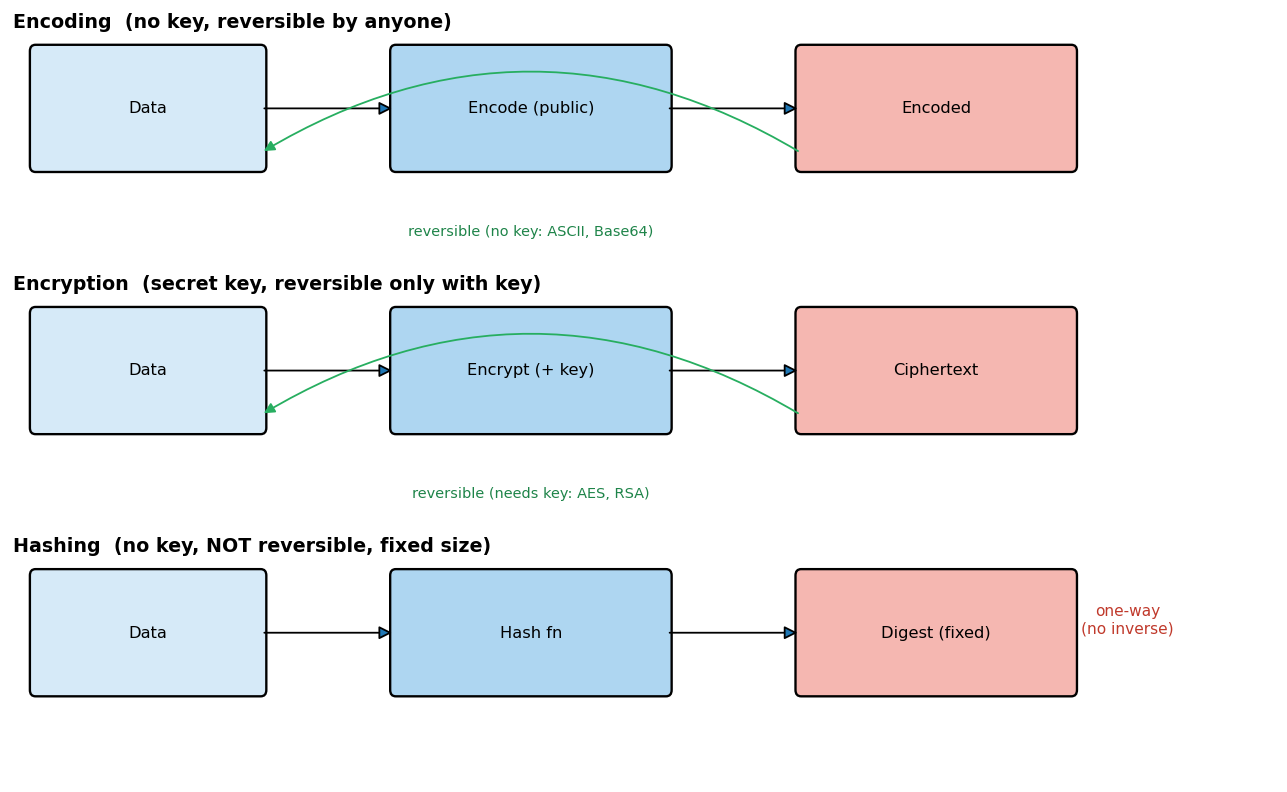
# Chapter 2 -- Encoding vs Encryption vs Hashing (one-way vs reversible, key vs no key)
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
from matplotlib.patches import FancyArrowPatch, FancyBboxPatch
fig, ax = plt.subplots(3, 1, figsize=(9, 6.4))
def row(a, title, mid, out, back, keynote):
def box(x,label,color,w=1.8):
a.add_patch(FancyBboxPatch((x,0.8),w,0.8,boxstyle="round,pad=0.05",facecolor=color,edgecolor="black"))
a.text(x+w/2,1.2,label,ha="center",va="center",fontsize=8.5)
box(0.2,"Data","#d6eaf8"); box(3.2,mid,"#aed6f1"); box(6.4,out,"#f5b7b1")
a.add_patch(FancyArrowPatch((2.0,1.2),(3.2,1.2),arrowstyle="->",mutation_scale=14))
a.add_patch(FancyArrowPatch((5.0,1.2),(6.4,1.2),arrowstyle="->",mutation_scale=14))
if back:
a.add_patch(FancyArrowPatch((6.4,0.95),(2.0,0.95),arrowstyle="->",mutation_scale=12,color="#27ae60",
connectionstyle="arc3,rad=0.25"))
a.text(4.2,0.35,"reversible "+keynote,ha="center",fontsize=8,color="#1e8449")
else:
a.text(8.7,1.2,"one-way\n(no inverse)",ha="center",fontsize=8,color="#c0392b")
a.set_xlim(0,10); a.set_ylim(0,2); a.axis("off"); a.set_title(title,fontsize=10,loc="left")
row(ax[0],"Encoding (no key, reversible by anyone)","Encode\n(public scheme)","Encoded",True,"(no key)")
row(ax[1],"Encryption (secret key, reversible only with key)","Encrypt\n(+ secret key)","Ciphertext",True,"(needs key)")
row(ax[2],"Hashing (no key, NOT reversible, fixed size)","Hash fn","Digest (fixed)",False,"")
plt.tight_layout(); plt.savefig("ch02_encoding_encryption_hashing.png", dpi=110)
print("Saved ch02_encoding_encryption_hashing.png")
Four Transformations Compared#
A frequent source of confusion is mixing up four operations that all change how data looks but serve very different goals. The diagram contrasts them.
flowchart TB
D[Data] --> E1[Encoding]
D --> E2[Encryption]
D --> H[Hashing]
D --> T[Tokenization]
E1 --> E1d["Reversible by anyone; no key; no confidentiality.<br/>Use: transport/storage (Base64)."]
E2 --> E2d["Reversible with a key; protects confidentiality.<br/>Use: TLS, files at rest."]
H --> Hd["One-way; not reversible; verifies integrity.<br/>Use: integrity, password verifiers."]
T --> Td["Surrogate token; real value kept in a vault.<br/>Use: PCI DSS card data."]
The crucial distinctions: encoding provides no security (anyone can reverse Base64); encryption is reversible only with a key and protects confidentiality; hashing is one-way and protects integrity, not confidentiality; and tokenization swaps a sensitive value for a surrogate token while the real value sits in a protected vault, the technique behind PCI DSS handling of card numbers. Calling Base64 “encryption” is the classic beginner error this comparison prevents.
2.2 Classical Ciphers and Why They Fall#
With the goals and the ground rule (Kerckhoffs’s principle) in hand, the natural way to build intuition is to watch weak systems fail. The classical ciphers below show, concretely, why amateur schemes collapse, and they teach the cryptanalyst’s habits we will rely on for the rest of the chapter.
The history of cryptography before the twentieth century is, in effect, a long demonstration of why intuition is a poor guide to security. Studying classical ciphers is valuable not for their practical use, which is nil, but because breaking them teaches the analytical habits of the cryptanalyst.
The simplest is the Caesar cipher, named for Julius Caesar, which shifts each letter a fixed number of positions through the alphabet. With a shift of three, A becomes D, B becomes E, and so on. The key is just the shift amount, of which there are only 25 useful values, so an attacker can simply try all of them, a brute-force attack, and read the one result that makes sense. A cipher whose entire keyspace can be searched in moments offers no security.
A monoalphabetic substitution cipher generalizes this by mapping each letter to an arbitrary other letter, giving a keyspace of 26 factorial, about 2 to the 88th power, far too large to brute force. Yet these ciphers fall easily to frequency analysis, first described by the ninth-century scholar al-Kindi. The insight is that a substitution cipher hides which letter each symbol represents but preserves how often each appears. Because the letter E is the most common in English, the most frequent ciphertext symbol very likely represents E, and so on down the distribution, supplemented by common digrams (TH, ER) and word patterns. The structure of the language leaks straight through the encryption.
The Vigenere cipher attempts to defeat frequency analysis by using a repeating keyword to apply different Caesar shifts to successive letters, flattening the frequency distribution. It resisted analysis for centuries and was called le chiffre indechiffrable, the indecipherable cipher. But it too falls: once the key length is found (by the Kasiski examination or by index-of-coincidence methods), the ciphertext splits into separate Caesar ciphers, each broken by frequency analysis. The deep lesson, which the one-time pad in the next section makes precise, is that a short, repeating key cannot securely encrypt a long message, because the repetition reintroduces exploitable structure.
The code cell below provides tools to experiment with the Caesar cipher and frequency analysis. Try the challenge ciphertexts and observe how quickly structure betrays the key.
Beyond substitution lies a second classical family, the transposition ciphers, which do not replace letters but rearrange them according to a secret pattern, such as writing the message into a grid by rows and reading it out by columns (the columnar transposition). Transposition preserves the letter frequencies of the plaintext, so a frequency count alone looks like normal language; the cryptanalyst must instead detect anagram structure and probable column orderings. Real historical systems often combined substitution and transposition to frustrate both attacks at once. The most sophisticated pre-computer machine, the German Enigma of the Second World War, used rotating wired rotors to create a polyalphabetic substitution that changed with every keypress, yielding an astronomically large key space. It was nonetheless broken by Allied cryptanalysts at Bletchley Park, led by Marian Rejewski’s earlier Polish work and by Alan Turing, who exploited operational mistakes, predictable message formats, and the machine’s one structural flaw (a letter never encrypted to itself) using electromechanical “bombes.” Enigma’s defeat is the historical bridge to the computer age and a permanent reminder that procedural and implementation errors, not just weak algorithms, decide real outcomes.
Classical versus Modern Ciphers#
Stepping back from the individual classical ciphers, it is worth drawing the line between the classical era just surveyed and the modern cryptography that occupies the rest of this chapter, because the distinction is conceptual, not merely chronological. Classical ciphers (Caesar, substitution, Vigenere, transposition, and electromechanical machines such as Enigma) operate on letters and rely for their security on the secrecy of the method or on modest key spaces; they fall to pencil-and-paper techniques such as frequency analysis or, today, to a fraction of a second of computer time. Modern ciphers operate on bits, assume the algorithm is fully public (Kerckhoffs’s principle), and base their security on computational hardness, mathematical problems believed infeasible to solve without the key, so that breaking them is not impossible in principle but is infeasible in practice for any realistic adversary.
Aspect |
Classical ciphers |
Modern ciphers |
|---|---|---|
Operate on |
Letters / characters |
Bits and bytes |
Security basis |
Secrecy of method, small key space |
Public algorithm, computational hardness |
Key sizes |
Tiny (a shift, a keyword) |
128-256 bits (symmetric), 2048+ (RSA) |
Broken by |
Frequency analysis, brute force |
Believed infeasible with correct use |
Examples |
Caesar, Vigenere, transposition, Enigma |
AES, ChaCha20, RSA, ECC, SHA-3 |
Performed by |
Hand or simple machines |
Computers (often with hardware acceleration) |
This shift, from secrecy-of-method to computational hardness over a public algorithm, is the dividing line of the field, and it is why the rest of this chapter is organized around the mathematical problems (factoring, discrete logarithms, and their elliptic-curve and lattice variants) that make modern security possible, and around the computing power that threatens it, the subject revisited in Section 2.15.
A Classification of Ciphers#
It helps to see the whole landscape of ciphers in one picture. The earliest known systematic classification of ciphers, along with the frequency-analysis technique used to break them, is credited to the ninth-century Arab polymath al-Kindi, whose work makes him a founder of cryptanalysis. A modern taxonomy extends his scheme to the computational era, organizing ciphers first by the classical-versus- modern divide and then by mechanism.
graph TD
C[Ciphers] --> CL[Classical]
C --> MO[Modern]
CL --> SUB[Substitution]
CL --> TRANS[Transposition]
SUB --> MONO[Monoalphabetic: Caesar, simple substitution]
SUB --> POLY[Polyalphabetic: Vigenere, Enigma]
TRANS --> COL[Columnar / rail-fence]
MO --> SYM[Symmetric: one shared key]
MO --> ASY[Asymmetric: public/private key pair]
SYM --> BLK[Block: AES, DES/3DES]
SYM --> STR[Stream: ChaCha20, RC4]
ASY --> FAC[Factoring-based: RSA]
ASY --> DLOG[Discrete-log / ECC: DH, ECDSA, EdDSA]
MO --> PQC[Post-quantum: lattice ML-KEM/ML-DSA, hash-based]
Reading the tree from the top, classical ciphers split into substitution (replacing symbols, either one fixed alphabet, monoalphabetic, or several, polyalphabetic) and transposition (rearranging symbols), while modern ciphers split into symmetric (block and stream, sharing one key) and asymmetric (built on factoring or discrete-logarithm hardness), with post-quantum families now joining the modern branch. Every cipher named in this chapter has a place on this tree, and locating an unfamiliar algorithm on it is the fastest way to grasp how it works and what it is good for.
# Chapter 2 -- Classical ciphers and frequency analysis (self-contained)
from collections import Counter
import string
def caesar(text, shift):
out = []
for ch in text:
if ch.isupper():
out.append(chr((ord(ch) - 65 + shift) % 26 + 65))
elif ch.islower():
out.append(chr((ord(ch) - 97 + shift) % 26 + 97))
else:
out.append(ch)
return "".join(out)
def caesar_bruteforce(cipher):
print("All 26 Caesar shifts (look for readable English):")
for s in range(26):
print(f" shift {s:2d}: {caesar(cipher, -s)[:60]}")
def letter_frequency(text):
letters = [c.lower() for c in text if c.isalpha()]
n = len(letters)
freq = Counter(letters)
print(f"Letter frequencies over {n} letters (English E~12.7%, T~9.1%, A~8.2%):")
for ch, cnt in freq.most_common(8):
print(f" {ch}: {cnt:4d} ({100*cnt/n:5.1f}%)")
# Demonstration
msg = "The quick brown fox jumps over the lazy dog near the old stone bridge."
ct = caesar(msg, 3)
print("Plaintext :", msg)
print("Caesar(+3):", ct)
print()
caesar_bruteforce("Wkh txlfn eurzq ira")
print()
# Frequency analysis on a longer substitution sample
sample = caesar(msg * 3, 7) # stand-in for a monoalphabetic ciphertext
letter_frequency(sample)
print("\\nChallenge: cipher = 'Ro)x~)|ynwm)vx{n)xw)lxoonn)}qjw)xw)R])|nl~{r}5' (try non-26 shifts)")
Plaintext : The quick brown fox jumps over the lazy dog near the old stone bridge.
Caesar(+3): Wkh txlfn eurzq ira mxpsv ryhu wkh odcb grj qhdu wkh rog vwrqh eulgjh.
All 26 Caesar shifts (look for readable English):
shift 0: Wkh txlfn eurzq ira
shift 1: Vjg swkem dtqyp hqz
shift 2: Uif rvjdl cspxo gpy
shift 3: The quick brown fox
shift 4: Sgd pthbj aqnvm enw
shift 5: Rfc osgai zpmul dmv
shift 6: Qeb nrfzh yoltk clu
shift 7: Pda mqeyg xnksj bkt
shift 8: Ocz lpdxf wmjri ajs
shift 9: Nby kocwe vliqh zir
shift 10: Max jnbvd ukhpg yhq
shift 11: Lzw imauc tjgof xgp
shift 12: Kyv hlztb sifne wfo
shift 13: Jxu gkysa rhemd ven
shift 14: Iwt fjxrz qgdlc udm
shift 15: Hvs eiwqy pfckb tcl
shift 16: Gur dhvpx oebja sbk
shift 17: Ftq cguow ndaiz raj
shift 18: Esp bftnv mczhy qzi
shift 19: Dro aesmu lbygx pyh
shift 20: Cqn zdrlt kaxfw oxg
shift 21: Bpm ycqks jzwev nwf
shift 22: Aol xbpjr iyvdu mve
shift 23: Znk waoiq hxuct lud
shift 24: Ymj vznhp gwtbs ktc
shift 25: Xli uymgo fvsar jsb
Letter frequencies over 168 letters (English E~12.7%, T~9.1%, A~8.2%):
l: 21 ( 12.5%)
v: 18 ( 10.7%)
a: 12 ( 7.1%)
y: 12 ( 7.1%)
o: 9 ( 5.4%)
u: 9 ( 5.4%)
k: 9 ( 5.4%)
b: 6 ( 3.6%)
\nChallenge: cipher = 'Ro)x~)|ynwm)vx{n)xw)lxoonn)}qjw)xw)R])|nl~{r}5' (try non-26 shifts)
Classical Ciphers in Code#
Classical ciphers are best understood by implementing them, and the companion repository (Appendix F) provides
short reference programs. The Caesar cipher simply shifts each letter by a fixed amount, modular over the
alphabet; the Java version below preserves case and wraps with % 26.
// CaesarCipher.java -- shift each letter by s (mod 26), preserving case
static StringBuffer encrypt(String text, int s) {
StringBuffer result = new StringBuffer();
for (int i = 0; i < text.length(); i++) {
char c = text.charAt(i);
if (Character.isUpperCase(c))
result.append((char)(((int)c + s - 65) % 26 + 65)); // 'A' = 65
else
result.append((char)(((int)c + s - 97) % 26 + 97)); // 'a' = 97
}
return result; // encrypt("STEVENS", 3) -> "VWHYHQV"
}
The Vigenere cipher strengthens Caesar by using a repeating keyword, so each position is shifted by a different amount, which defeats naive single-shift frequency analysis (though, as Section 2.2 explains, it still falls to Kasiski and index-of-coincidence attacks). This C version repeats the key to the message length and adds modulo 26.
/* vigenerecipher.c -- repeat key to message length, then add mod 26 */
for (i = 0, j = 0; i < msgLen; ++i, ++j) { /* build the running key */
if (j == keyLen) j = 0;
newKey[i] = key[j];
}
for (i = 0; i < msgLen; ++i) /* encrypt */
encryptedMsg[i] = ((msg[i] + newKey[i]) % 26) + 'A';
for (i = 0; i < msgLen; ++i) /* decrypt */
decryptedMsg[i] = (((encryptedMsg[i] - newKey[i]) + 26) % 26) + 'A';
These two programs make the chapter’s central lesson concrete: both are trivial to implement and trivial to break, which is exactly why modern cryptography replaced substitution with the rigorously analyzed primitives that follow.
2.3 Perfect Secrecy and the One-Time Pad#
Breaking classical ciphers raises an obvious question: is unbreakable encryption even possible? Shannon answered yes, and the answer reshapes how we think about every cipher that follows.
In 1949 Claude Shannon placed cryptography on a rigorous mathematical footing by defining perfect secrecy. A cipher is perfectly secret if observing the ciphertext gives an adversary no information whatsoever about the plaintext, beyond what they knew before. Formally, for every plaintext m and every ciphertext c, the probability of m given c equals the probability of m: the ciphertext and plaintext are statistically independent. An adversary with unlimited computing power learns nothing.
Remarkably, perfect secrecy is achievable, by the one-time pad (OTP). The pad is a random key as long as the message; encryption combines each plaintext bit with the corresponding key bit using exclusive-or (XOR), and decryption XORs again with the same key. If the key is truly random, used only once, kept secret, and at least as long as the message, the result is provably unbreakable. The intuition is that for any observed ciphertext, every plaintext of that length is equally possible under some key, so the ciphertext reveals nothing.
Going Deeper (graduate/research): why OTP is optimal and why we abandon it
Shannon proved a stronger negative result: perfect secrecy requires the key space to be at least as large as the message space, so the key must be at least as long as the message. This is why perfect secrecy does not scale: to send a gigabyte secretly you must first share a gigabyte of secret key, which merely relocates the problem. Modern cryptography therefore trades Shannon’s information-theoretic security for computational security: ciphers like AES are not unbreakable in principle, but breaking them is believed to require computational effort far beyond any feasible adversary. The formal goal becomes semantic security (equivalently, indistinguishability under chosen-plaintext attack, IND-CPA): no efficient adversary can distinguish the encryptions of two chosen messages with more than negligible advantage. Block ciphers in a proper mode, seeded by a short key, approximate the OTP’s guarantee against bounded adversaries while keeping the key small.
The one-time pad also illustrates how cryptography fails in practice. The “one-time” requirement is absolute: if the same pad encrypts two messages, XORing the two ciphertexts cancels the key and leaks the XOR of the plaintexts, which is often enough to recover both. This exact mistake broke Soviet traffic in the mid-twentieth century VENONA project, when pad pages were reused. The pattern, key reuse destroys security, recurs throughout cryptography, from the OTP to stream ciphers to the nonce reuse that breaks modern authenticated encryption.
Going Deeper (graduate/research): the semantic-security game
Computational security is defined through games between a challenger and an adversary. In the indistinguishability under chosen-plaintext attack (IND-CPA) game, the adversary may encrypt arbitrary messages, then submits two equal-length messages m0 and m1; the challenger secretly flips a bit b and returns the encryption of m_b; the adversary, still able to request more encryptions, must guess b. The scheme is IND-CPA secure if no efficient adversary guesses correctly with probability more than negligibly above one-half. This formalism explains several earlier points at once. It is why encryption must be randomized or nonce-based: a deterministic scheme loses the game instantly, because the adversary just encrypts m0 and m1 and compares. It is why ECB fails: identical blocks are distinguishable. And it scales up to IND-CCA, where the adversary also gets a decryption oracle, the model that authenticated encryption is built to satisfy. Reasoning in terms of what an adversary can distinguish, rather than merely what they can read, is the conceptual leap that separates modern provable-security cryptography from its classical predecessors, and it is the foundation on which Boneh and Shoup, and Katz and Lindell, build their treatments.
XOR, the One-Time Pad, and Perfect Secrecy, Formally#
The one-time pad introduced above is worth stating precisely, because it is the one cipher whose security can be proved with no assumptions about the attacker’s computing power, and because every later, weaker notion of security is best understood as a deliberate relaxation of it. The pad’s engine is the exclusive-or (XOR, written as the symbol used below), the bitwise operation that returns 1 when its two input bits differ and 0 when they agree. XOR is its own inverse: for any bits a and k, (a XOR k) XOR k = a. That single algebraic fact is the whole cipher. If the message is an n-bit string m and the key is an n-bit string k, then encryption is E(k, m) = m XOR k = c, and decryption is D(k, c) = c XOR k = m. XORing with the key once scrambles; XORing with the same key again unscrambles.
Perfect secrecy is the strongest confidentiality goal there is. Informally, after intercepting the ciphertext, an adversary, no matter how clever or well-equipped, learns absolutely nothing about the plaintext: not “almost nothing,” but nothing at all. Stated formally, a scheme is perfectly secret if for every pair of messages m0 and m1 and every ciphertext c,
where the probability is over the random key k. Every plaintext is equally likely to have produced any given ciphertext, so the ciphertext carries zero information about which message was sent. Claude Shannon proved in 1949 that perfect secrecy requires the key to be at least as long as the message, which is exactly what the one-time pad provides.
The Three Iron Laws of the One-Time Pad#
The pad delivers perfect secrecy only when three conditions hold simultaneously. Break any one and the guarantee collapses, so they are worth stating as laws rather than guidelines.
The key is as long as the message. The pad must supply one fresh key bit for every message bit (|k| = |m|). This is the price Shannon proved is unavoidable for perfect secrecy and the reason the pad is impractical for bulk data.
The key is truly random. Every key must be drawn uniformly at random, for example by a physical process equivalent to flipping a fair coin per bit. A key from a predictable or low-entropy source destroys the proof, which is why this section connects directly to the randomness discussion of Section 2.4.
The key is used exactly once. Reuse is fatal, hence the name “one-time.” A pad used twice is no longer a one-time pad; it is a “two-time pad,” and it leaks.
Warning: key reuse turns a perfect cipher to glass (the two-time pad)
Suppose two messages are encrypted under the same pad key K: C1 = M1 XOR K and C2 = M2 XOR K. An attacker who XORs the two ciphertexts cancels the key entirely:
C1 XOR C2 = (M1 XOR K) XOR (M2 XOR K) = M1 XOR M2.
The result is the XOR of the two plaintexts, with the key gone. In natural-language text this is readily unraveled by crib-dragging: the space character (ASCII 32) is extremely common, so guessing a space at each position and XORing reveals letters of the other message, which then bootstraps the rest like a crossword. This exact technique broke real wartime ciphers when desperate operators reused key material. The lesson recurs throughout this chapter: a mathematically perfect scheme is only as strong as the discipline with which its keys are managed.
There is a second, subtler lesson. The one-time pad provides perfect confidentiality but no integrity.
Because flipping a bit of the ciphertext flips exactly the corresponding bit of the plaintext, an attacker who
knows or guesses part of the message can surgically alter it: changing a ciphertext so that NOW ATTACK
decrypts to NOT ATTACK requires only flipping the bits that distinguish W from T, with no key. Perfect
secrecy says nothing about whether a message arrives unmodified, which is precisely why authenticated
encryption (Section 2.8) exists. This same malleability is the property the indistinguishability notions below
are designed to reason about rigorously.
From Information-Theoretic to Computational Security#
The one-time pad’s perfection comes at a cost no real system can usually pay: a truly random key as long as all the data ever sent, delivered in advance over a secure channel. The entire edifice of modern cryptography is the project of getting almost the same guarantee from short, reusable keys, by giving up security against an adversary with unlimited computing power and settling instead for security against any realistic adversary. This is the distinction between two security models.
Information-theoretic (unconditional) security, which the one-time pad achieves, holds even against an attacker with infinite time and computation. Computational security, which AES, RSA, and elliptic-curve schemes target, holds only against an attacker bounded by feasible resources, modeled formally as a probabilistic polynomial-time (PPT) algorithm: one that must finish within a number of steps that grows only polynomially in a security parameter (such as the key length in bits). A computationally secure scheme can, in principle, be broken by brute force, but the work required is so astronomically large that it will not happen before the sun burns out. We accept that trade because it buys us short keys we can actually distribute and reuse.
To make “infeasible to break” precise, cryptographers measure an attacker’s success with two linked ideas. An adversary’s advantage is how much better it does than blind guessing; for a yes/no challenge, an advantage of 0 means it is doing no better than a coin flip. A quantity is negligible if it shrinks faster than the inverse of every polynomial in the security parameter, that is, for every polynomial poly there is a threshold beyond which the quantity stays below 1/poly. A scheme is deemed secure when every PPT adversary has only negligible advantage. With this vocabulary we can finally define security not by describing a cipher but by describing a game the attacker is challenged to win.
Game-Based (Provable) Security and Ciphertext Indistinguishability#
Modern definitions of confidentiality are stated as security games (also called challenge experiments): a formal contest between an adversary and a challenger. The cryptosystem is declared secure if no efficient adversary can win the game with probability meaningfully better than random guessing. This style, called provable or reductionist security, is powerful because a proof reduces breaking the scheme to solving a problem believed to be hard (factoring, discrete logarithms), so a successful attack would also solve that underlying problem.
The central confidentiality game is ciphertext indistinguishability. Intuitively, a scheme has this property if an adversary cannot tell which of two messages a ciphertext encrypts, even when the adversary chose both messages. The canonical instance is indistinguishability under chosen-plaintext attack (IND-CPA), defined by the following game for a public-key scheme (the symmetric version simply replaces the public key with an encryption oracle that encrypts any plaintext the adversary submits):
The challenger generates a key pair (PK, SK) from a security parameter k and gives PK to the adversary, keeping SK.
The adversary performs any polynomially bounded amount of computation and encryption it likes.
The adversary chooses two distinct, equal-length plaintexts M0 and M1 and sends them to the challenger.
The challenger picks a bit b in {0, 1} uniformly at random and returns the challenge ciphertext C = E(PK, Mb).
The adversary computes further if it wishes, then outputs a guess b’ for b.
The scheme is IND-CPA secure if every PPT adversary guesses b correctly with probability only negligibly above one-half, that is, its advantage is negligible. A crucial consequence is that IND-CPA is impossible for a deterministic cipher: if encryption were deterministic, the adversary would simply encrypt M0 and M1 itself and compare against C. IND-CPA therefore forces encryption to be randomized (or nonce-based), which is why textbook RSA and ECB mode (Section 2.6) fail this basic bar while their randomized counterparts pass.
flowchart TD
CH[Challenger: generate PK, SK, publish PK] --> ADV1[Adversary: encrypt / compute freely]
ADV1 --> SUB[Adversary submits M0, M1]
SUB --> FLIP[Challenger picks secret bit b at random]
FLIP --> CHAL[Return challenge C = E PK, Mb]
CHAL --> ADV2[Adversary computes further]
ADV2 --> GUESS{Adversary outputs guess b'}
GUESS --> WIN[Secure if Pr b' = b is only negligibly above 1/2]
The Attack-Model Ladder: CPA, CCA1, CCA2#
The strength of an indistinguishability notion depends on what the adversary is allowed to do, which is fixed by the attack model. Three models form a ladder of increasing adversary power, all using the same challenge game but granting different oracle access.
IND-CPA (chosen-plaintext attack): the adversary may encrypt any plaintexts it likes (it has an encryption oracle, or simply the public key) but cannot decrypt.
IND-CCA1 (non-adaptive chosen-ciphertext attack, “lunchtime attack”): the adversary additionally gets a decryption oracle, but only before it receives the challenge ciphertext.
IND-CCA2 (adaptive chosen-ciphertext attack): the adversary may keep querying the decryption oracle even after receiving the challenge, with the sole restriction that it may not ask the oracle to decrypt the challenge ciphertext itself (which would make the game trivial).
These notions are strictly ordered: IND-CCA2 implies IND-CCA1 implies IND-CPA. A scheme secure in a stronger model is automatically secure in the weaker ones, so IND-CCA2 is the strongest of the three and the modern default target for general-purpose encryption. This ladder is the formal counterpart of the decryption-oracle discussion in Section 2.8: a padding-oracle attack is exactly a real-world demonstration that a scheme fails IND-CCA2 because its decryption behavior leaks.
Definition: semantic security
Semantic security captures the intuition that a ciphertext reveals no partial information about the plaintext: anything an adversary can compute about the message given the ciphertext, it could also compute without it. It is one of the oldest rigorous confidentiality definitions (Goldwasser and Micali). The key fact is that semantic security under chosen-plaintext attack is equivalent to IND-CPA, so proofs use the two interchangeably and indistinguishability serves as the convenient working definition.
Confidentiality Meets Integrity: Non-Malleability and the Relations#
Indistinguishability is a confidentiality property: it says the attacker cannot read the plaintext. Non-malleability (NM) is, by contrast, an integrity-flavored property: given a ciphertext of m, the adversary cannot produce a different ciphertext whose plaintext is meaningfully related to m (for example, m + 1, or m with one block changed). The one-time pad and CTR mode are extreme examples of malleable schemes, as shown above. Remarkably, these confidentiality and integrity notions are tightly connected, and some are outright equivalent. Writing A implies B for “property A guarantees property B,” A iff B for equivalence, and A does-not-imply B for a separation, the standard relations are:
Relation |
Meaning |
|---|---|
IND-CPA iff semantic security under CPA |
Indistinguishability and semantic security are the same notion under chosen-plaintext attack. |
NM-CPA implies IND-CPA |
Non-malleability under CPA is strictly stronger than indistinguishability under CPA; it gives confidentiality for free. |
NM-CPA does not imply IND-CCA2 |
Non-malleability under the weaker CPA model is not enough to reach adaptive-CCA security; the gap is real. |
NM-CCA2 iff IND-CCA2 |
Under the strongest, adaptive chosen-ciphertext model, non-malleability and indistinguishability coincide exactly. |
The last equivalence is the surprising one: at the IND-CCA2 level, a property about message integrity (non-malleability) turns out to be identical to a property about message confidentiality (indistinguishability). This is one reason authenticated encryption is so central. By guaranteeing integrity it simultaneously delivers the strongest confidentiality notion, and it is why the chapter keeps returning to “use AEAD” as the practical distillation of decades of theory. These relations were established by Bellare, Desai, Pointcheval, and Rogaway (1998).
A related practical idea is that some systems deliberately make ciphertext indistinguishable from random bits. Most IND-CPA schemes already produce output that looks random, but when this is made an explicit goal it enables deniable encryption (a hidden message cannot be proven to exist, supporting plausible deniability), frustrates traffic analysis, and underlies data-hiding and steganographic systems and hidden volumes such as those once offered by TrueCrypt.
Knowledge Check
Why can no deterministic encryption scheme be IND-CPA secure?
Order IND-CPA, IND-CCA1, and IND-CCA2 from weakest to strongest, and say what distinguishes CCA1 from CCA2.
Which single relation shows that, at the highest security level, integrity (non-malleability) and confidentiality (indistinguishability) become the same property?
Answers: (1) If encryption is deterministic, the adversary simply encrypts its own M0 and M1 and compares with the challenge ciphertext, winning with certainty; IND-CPA forces randomized/nonce-based encryption. (2) IND-CPA (weakest) is less than IND-CCA1 is less than IND-CCA2 (strongest); CCA1 grants a decryption oracle only before the challenge (“lunchtime”), while CCA2 allows decryption queries after the challenge too (excluding the challenge ciphertext itself). (3) NM-CCA2 iff IND-CCA2: under adaptive chosen-ciphertext attack, non-malleability and indistinguishability are equivalent.
IND-CPA^D: When Decryptions Leak (Security for Approximate Homomorphic Encryption)#
The CPA/CCA ladder above assumed the attacker never sees honest decryptions of its chosen ciphertexts. That assumption quietly fails in one of the most important modern settings: homomorphic encryption, where a server computes on ciphertexts and the results are decrypted and shared. Here the natural threat is an adversary who is merely honest-but-curious yet gets to observe the decrypted outputs of computations. This motivated a refinement of IND-CPA called IND-CPA^D (read “IND-CPA^D”), meaning IND-CPA with a decryption oracle, introduced by Li and Micciancio at EUROCRYPT 2021. In the IND-CPA^D game the adversary may, in addition to encrypting, submit ciphertexts (including the results of homomorphic evaluations on its chosen inputs) and receive their decryptions, then must still distinguish which of two message streams was encrypted. For an exact scheme, where decryption returns precisely the encrypted plaintext, IND-CPA^D collapses back to ordinary IND-CPA. The notion only bites when decryption is approximate.
That is exactly the case for CKKS (Cheon-Kim-Kim-Song), the approximate-arithmetic homomorphic scheme used for real-valued data and, as Chapter 17 describes, the engine of the author’s SigML and SplitML work. CKKS deliberately tolerates a small decryption error so it can do fast approximate arithmetic, and that error is the problem. Li and Micciancio showed that approximate FHE schemes leak the secret key once decryptions are shared. The intuition is direct: an RLWE ciphertext has the form ct = (as + m + e, -a), and CKKS decryption returns m + e rather than m. An adversary who knows the input message m (or its computation) can subtract it to recover the noise e, and from (as + e) with known a it can solve for the secret key s. The slogan from the OpenFHE security notes captures it: one should treat the RLWE error e as part of the secret key. The attacks are not theoretical curiosities; they run in expected polynomial time and recover the full key with high probability and modest effort, and they work against passive adversaries. The same paper introduced a companion key-recovery notion, KR-D (key recovery under decryption).
The fix is noise flooding (also called smudging): make decryption a randomized procedure that adds deliberately large extra noise to mask the residual error before the result is released. For a CKKS ciphertext ct = (c0, c1), flooded decryption samples a discrete Gaussian z over the polynomial ring and returns c0 + c1*s + z (mod q). If the application wants s bits of statistical security against an adversary expected to make tau queries, the OpenFHE analysis sets the standard deviation to
where ct.t is an estimate of the ciphertext’s own error. Taking s of at least 30 bounds even an inefficient
adversary’s success probability to about 2^(-30), roughly one in a billion. Li and Micciancio proved that
post-processing CKKS decryption with such a Gaussian mechanism achieves IND-CPA^D for large enough noise, with
a nearly matching lower bound, and follow-up work by Li, Micciancio, Schultz, and Sorrell (CRYPTO 2022) framed
this with differential privacy and confirmed that the required noise is substantial, which directly eats into
the message precision CKKS can offer. Noise flooding is the same idea long used as noise-smudging in
threshold and multi-party FHE, where partial decryptions must not leak secret-key shares; OpenFHE exposes
this as a NOISE_FLOODING_MULTIPARTY mode for distributed-decryption settings.
Warning: estimating the flood is itself a vulnerability (the dynamic-estimation attack)
The catch is the term ct.t. CKKS noise growth is input-dependent once a multiplication is involved, so the amount of flooding must be estimated per computation, and a naive estimate can leak. The UCSD dynamic-estimation attack demonstrates this against PALISADE’s CKKS: it homomorphically evaluates a circuit such as C = x1x2 + x3x4 chosen so the exact result is always 0 while the noise scales with the input magnitudes. Because the countermeasure sizes its added noise from an input-dependent estimate, simply observing how much noise the system adds (the decrypted “zero” varies by orders of magnitude) breaks IND-CPA^D. The lesson is that a defense parameterized by secret-dependent quantities can reopen the very oracle it was meant to close.
OpenFHE answers this with a disciplined two-phase static noise estimation. First, in an
EXEC_NOISE_ESTIMATION mode, it runs the target computation on a fresh, independent key pair (not the user’s)
over representative data and measures the precision loss in the imaginary slots of the decrypted plaintext to
estimate the noise bound ct.t, a heuristic validated by Costache and colleagues (2022). Then, in an
EXEC_EVALUATION mode, it runs the real computation under the user’s key and applies Gaussian flooding with the
sigma above; OpenFHE even allows the estimation to run in 64-bit CKKS and the evaluation in 128-bit CKKS. The
reference implementation lives in ckks-noise-flooding.cpp, with the model documented in the library’s
CKKS_NOISE_FLOODING.md.
Two further results round out the current picture. First, IND-CPA^D is not only an approximate-FHE concern: Cheon, Choe, Passelegue, Stehle, and Suvanto (2024) mounted KR-D attacks against the IND-CPA^D security of exact schemes too (BFV and BGV in OpenFHE, DM/CGGI in TFHE-rs, and CKKS bootstrapping in Lattigo) by exploiting rare decryption failures, which leak the secret much as approximate noise does. Second, the noise cost is being driven down: Ogilvie (ASIACRYPT 2025) achieves provable IND-CPA^D and KR-D security with substantially less added noise by using the HintLWE problem, observing that the noise from CKKS rescaling acts as a linear hint on the secret, so in rescaling-dominated regimes as little as about two bits of extra precision loss can restore strong protection against passive key recovery, and with a noise strategy independent of the number of queries.
Going Deeper (graduate/research): choosing flooding parameters
When deploying CKKS where decryptions are shared (the SigML/SplitML setting of Chapter 17), the security target
is IND-CPA^D, not plain IND-CPA. Practically: (1) decide a statistical security level s (>= 30, often 40 to 64)
and an expected query budget tau; (2) obtain a sound, data-independent noise estimate via a two-phase static
estimation on an independent key, never from the live secret-key ciphertexts; (3) apply Gaussian flooding with
sigma = sqrt(12*tau)*2^(s/2)*ct.t before releasing any decryption; (4) in threshold or multiparty decryption,
use smudging on each partial decryption (OpenFHE’s NOISE_FLOODING_MULTIPARTY); and (5) budget for the
precision loss the flooding imposes, or exploit rescaling-hint techniques to reduce it. Treat any decryption
result shared outside the trust boundary as an oracle query, and size the flood for the worst case.
This refinement closes the loop on the indistinguishability hierarchy: IND-CPA and the CCA ladder govern ordinary encryption, while IND-CPA^D extends the same game-based methodology to schemes whose decryptions are deliberately approximate or occasionally failing, exactly the schemes that make privacy-preserving computation on encrypted data possible. We now leave the security definitions and return to the engineering question of where good keys come from in the first place.
Real-World Case: The ANC’s One-Time Pad and Operation Vula#
The one-time pad is not merely a textbook idealization; it has been the backbone of clandestine communication when nothing less than perfect secrecy would do. A striking example is the African National Congress (ANC) in the final decade of apartheid in South Africa, as documented by Tim Jenkin, the ANC communications officer who built the system, and reported by MyBroadband (2015).
With ANC leaders in exile or imprisoned and the underground unable to talk safely to headquarters-in-exile in Lusaka, the movement adopted the one-time pad precisely because it is, in theory, uncrackable. Early on, messages were enciphered by hand with paper pads (slow and cumbersome) and then sent electronically through a clever channel: the ciphertext digits were turned into dual-tone multi-frequency (DTMF) telephone tones using a generator disguised as a pocket calculator, recorded onto a cassette, and played from a payphone into a “message drop” answering machine; a matching miniaturized decoder turned received tones back into digits for manual decryption. For Operation Vula, which infiltrated leaders such as Mac Maharaj into South Africa, Jenkin and Ronnie Press (1984 to 1987) wrote a program to automate the pad: characters were mapped to values (first 7-bit, later 8-bit ASCII), combined with the key by modular addition and then by bitwise XOR, exactly the operation defined earlier in this section. They deliberately built their own pad-based tool rather than use commercial or open-source software, citing fear of backdoors a quarter-century before the Snowden disclosures, while acknowledging the usual rule “do not invent your own cryptography.”
This case study is valuable because it shows all three iron laws being honored under operational pressure. The random key material was distributed on 1.44 MB floppy disks (“stiffies”) filled with random data, and after any portion of key was used to encrypt or decrypt, that region of the disk was scrubbed by repeatedly overwriting it with zeros, enforcing the use-once law physically. Key distribution, the perennial hard part of the pad, depended on couriers: a sympathetic KLM flight attendant, Antoinette Vogelsang, recruited through Conny Braam of the Dutch anti-apartheid movement, smuggled in the disks and equipment. Jenkin notes that had she handed copies to the authorities, the whole system would have been compromised, a vivid reminder that the security of even a perfect cipher reduces to the security of its key channel. The system ultimately carried confidential messages between Nelson Mandela and Oliver Tambo for the first time since the early 1960s. The lesson for this chapter is the same one the theory predicts: the one-time pad’s mathematical perfection is real, but it lives or dies by key length, key randomness, key-use discipline, and above all key distribution.
2.4 Randomness: True, Pseudo, and Cryptographically Secure#
Perfect secrecy depended entirely on one assumption we glossed over, a truly random key. That assumption is so load-bearing, and so often violated in practice, that it deserves a section of its own before we build real ciphers on top of it.
Every cryptographic guarantee in the previous section rested on one phrase: truly random key. Randomness is the silent foundation of cryptography, and weak randomness is one of the most common and catastrophic real-world failures. We must distinguish three notions.
True randomness comes from physical, unpredictable processes: electronic noise, radioactive decay,
or timing jitter. Operating systems gather such entropy and expose it (for example through Linux
/dev/random and the getrandom system call). True entropy is the gold standard but can be slow to
collect.
Pseudo-randomness is produced by deterministic algorithms, pseudo-random number generators
(PRNGs), that stretch a small seed into a long sequence that looks random by statistical tests. The
classic example is the linear congruential generator (LCG), which computes each value from the
previous one as x = (a*x + c) mod m. LCGs are fast and fine for simulations and games, but they are
catastrophically insecure for cryptography: given a few outputs, an attacker can solve for the internal
state and predict all past and future values. General-purpose generators such as the Mersenne Twister
(Python’s default random module) are likewise predictable and must never be used for keys, tokens, or
nonces.
Cryptographically secure pseudo-random number generators (CSPRNGs) are PRNGs with an additional
guarantee: even an adversary who sees a long run of output cannot predict the next bit with advantage
better than chance, and cannot recover the internal state. In Python, secrets and
random.SystemRandom (backed by os.urandom) are CSPRNGs; the plain random module is not. The
practical rule is simple and worth memorizing: for anything security-sensitive, use a CSPRNG.
Predictable randomness has broken real systems repeatedly, from a 2008 Debian OpenSSL bug that
shrank the key space to a few thousand possibilities, to cryptocurrency wallets drained because their
keys were generated with weak entropy.
Where does true entropy actually come from? Operating systems harvest unpredictability from physical
events, the precise timing of interrupts, keystrokes, mouse movement, and disk activity, and many modern
CPUs include a hardware random-number generator (Intel’s RDRAND, for example) seeded by thermal noise.
This entropy is collected into a pool that seeds a CSPRNG. A long-standing point of confusion on Linux is
the difference between /dev/random and /dev/urandom: historically the former could block waiting for
“fresh” entropy while the latter would not, but on modern kernels, once the pool has been initialized
once, both are cryptographically secure, and the recommended interface is the getrandom system call.
The real-world failures are sobering. Embedded devices and virtual machines often boot with little
entropy and have generated predictable keys at scale; a famous 2012 study found large numbers of TLS and
SSH keys sharing factors because devices generated them before gathering enough randomness. The
operational takeaways are to ensure adequate entropy at first boot, to prefer the OS CSPRNG over any
home-grown generator, and to be especially careful in virtualized and embedded environments.
# Chapter 2 -- Randomness: predictable PRNG vs CSPRNG
import secrets
# A linear congruential generator (predictable!) -- glibc-style constants
class LCG:
def __init__(self, seed): self.state = seed
def next(self):
self.state = (1103515245 * self.state + 12345) & 0x7fffffff
return self.state
lcg = LCG(seed=42)
outputs = [lcg.next() for _ in range(5)]
print("LCG outputs :", outputs)
# An attacker who knows the constants reproduces the stream exactly:
attacker = LCG(seed=42)
print("Attacker copy :", [attacker.next() for _ in range(5)])
print("=> A deterministic PRNG with a known/recovered seed is fully predictable.\\n")
# CSPRNG: unpredictable, suitable for keys and tokens
print("Secure 256-bit key :", secrets.token_hex(32))
print("Secure URL-safe token:", secrets.token_urlsafe(24))
print("Secure dice roll 1-6 :", 1 + secrets.randbelow(6))
print("\\nRule: use `secrets` / os.urandom for keys, nonces, tokens; never `random` for security.")
LCG outputs : [1250496027, 1116302264, 1000676753, 1668674806, 908095735]
Attacker copy : [1250496027, 1116302264, 1000676753, 1668674806, 908095735]
=> A deterministic PRNG with a known/recovered seed is fully predictable.\n
Secure 256-bit key : 08270a70a325b02c7a87f72ec8b0c97efcc14e0006b2a7c11173b376f3987a57
Secure URL-safe token: oEU0-PD9WAGucGokfYWXr8x1VN7yHh2V
Secure dice roll 1-6 : 5
\nRule: use `secrets` / os.urandom for keys, nonces, tokens; never `random` for security.
Insecure versus Cryptographically Secure Randomness in Code#
The distinction between an ordinary pseudorandom generator and a cryptographically secure one (CSPRNG) is not
academic; in Java it is the difference between two classes. java.util.Random is a fast but predictable
linear-congruential generator, seeded from the clock and fully recoverable from a few outputs, so it must never
be used for keys, nonces, tokens, or IVs. java.security.SecureRandom is a CSPRNG suitable for
cryptographic use.
// UnsecureRandom.java -- DO NOT use for security
import java.util.Random;
Random rand = new Random(); // predictable LCG; same seed -> same stream
int x = rand.nextInt(10);
// BetterRandom.java -- use this for keys, nonces, IVs, tokens
import java.security.SecureRandom;
SecureRandom rand = new SecureRandom(); // CSPRNG
int x = rand.nextInt(10);
The two programs look almost identical, and that is the danger: the only visible change is the class name, yet the security consequence is total. This is the code-level form of the “randomness” requirement that underpins the one-time pad (Section 2.3), nonce uniqueness (Section 2.8), and key generation everywhere in this chapter.
2.5 Symmetric Encryption: Stream and Block Ciphers#
Armed with secure randomness, we can finally build the practical, scalable ciphers that protect real data. We trade Shannon’s perfect secrecy for computational security and gain something invaluable: short keys that encrypt long messages.
Symmetric cryptography uses a single shared secret key for both encryption and decryption. It is fast and efficient, making it the workhorse for encrypting bulk data, but it raises the key distribution problem: the two parties must somehow share the secret key over a secure channel before they can communicate, a problem solved later by public-key methods. Symmetric ciphers come in two families.
Stream ciphers encrypt data one bit or byte at a time by generating a pseudo-random keystream from the key and XORing it with the plaintext, much like a practical approximation of the one-time pad with a short key. They are fast and well suited to streaming data, but they are fragile: reusing a keystream is fatal, exactly as with the OTP. Modern stream ciphers such as ChaCha20 are widely used, notably in TLS and in mobile devices, and the older RC4 is now deprecated because of fatal biases.
Block ciphers encrypt fixed-size blocks of bits at a time, typically 128 bits, transforming a whole block under the key. The dominant block cipher is the Advanced Encryption Standard (AES), selected by the U.S. National Institute of Standards and Technology in 2001 (the Rijndael algorithm by Daemen and Rijmen) to replace the aging Data Encryption Standard (DES). DES had a 56-bit key that modern hardware brute-forces in hours; AES supports 128, 192, and 256-bit keys and remains secure.
Internally, AES is a substitution-permutation network that applies several rounds (10, 12, or 14 depending on key size) of four operations to a 4-by-4 byte state: SubBytes (a non-linear byte substitution through an S-box, providing Shannon’s confusion), ShiftRows and MixColumns (linear mixing that spreads each byte’s influence across the block, providing diffusion), and AddRoundKey (XOR with a round key derived from the main key by the key schedule). Confusion obscures the relationship between key and ciphertext; diffusion ensures that changing one plaintext bit changes about half the ciphertext bits, the avalanche effect. You do not need to implement AES, modern CPUs even have dedicated AES-NI instructions, but you must understand that a block cipher alone only encrypts one block. To encrypt a real message of many blocks, we need a mode of operation, the subject of the next section, and the choice of mode is where security is most often won or lost.
It is worth understanding the structure AES replaced, because it still appears in legacy systems and in exam questions. The Data Encryption Standard (DES), standardized in 1977, is built on a Feistel network, a design that splits each block in half and, over sixteen rounds, repeatedly mixes one half into the other using a round function and round keys. The Feistel structure has an elegant property: the same circuitry performs encryption and decryption simply by reversing the order of round keys, which made hardware cheap. DES’s fatal weakness was not its design but its 56-bit key, far too small; by the late 1990s purpose-built machines and distributed efforts brute-forced DES keys in days, then hours. The stop-gap Triple DES (3DES) applied DES three times with multiple keys to enlarge the effective key length, but it is slow, has a small 64-bit block that invites birthday-bound attacks on large data volumes (the Sweet32 attack), and is now deprecated. AES, a substitution-permutation network rather than a Feistel cipher, with 128-bit blocks and 128- to 256-bit keys, resolved all of these issues and is the symmetric standard today. The lesson for selecting cryptography is concrete: key length and block size are not academic parameters but the difference between secure and broken.
Before detailing block ciphers, it is worth fixing the broader trade-off that explains why symmetric cryptography remains indispensable despite the elegance of public-key methods covered later. Symmetric ciphers are typically several orders of magnitude faster than asymmetric ones and produce no ciphertext expansion to speak of, which is why essentially all bulk data, disk volumes, network streams, database fields, is protected symmetrically. The price is the key-distribution problem, and the standard architecture resolves it through hybrid encryption: use a slow public-key operation once, only to establish or transport a fresh symmetric session key, then encrypt all the actual data with that fast symmetric key. TLS, encrypted email, and messaging apps all follow this pattern, and recognizing it now will make the later sections on RSA, Diffie-Hellman, and TLS fall into place as solutions to the single problem this section sets up.
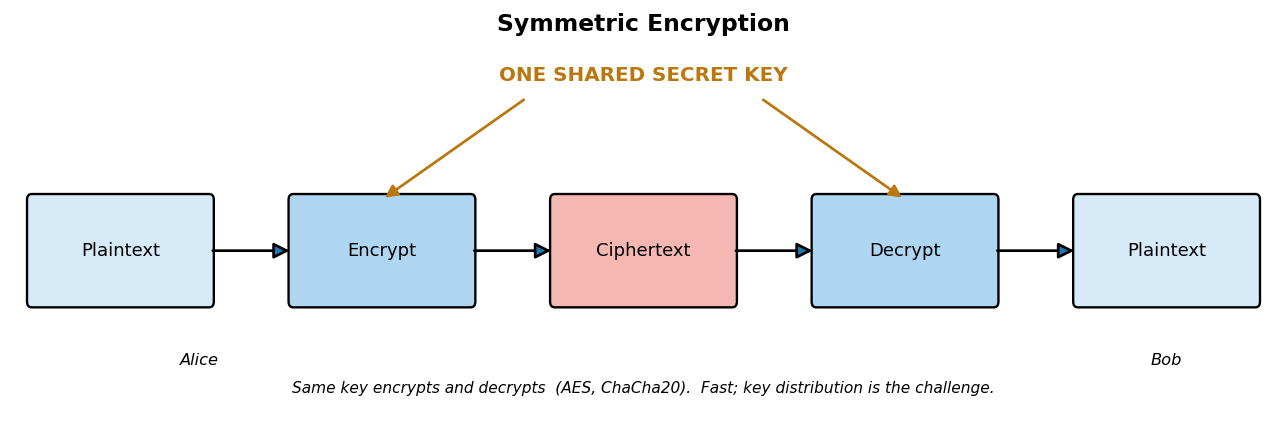
In symmetric encryption, the same secret key is used for both encryption and decryption, as the diagram shows. Alice and Bob must both hold the identical key, which is why secure key distribution is the central challenge.
flowchart LR
P1[Plaintext] -->|Encrypt| C[Ciphertext]
C -->|Decrypt| P2[Plaintext]
K([Shared secret key]) -.-> |used to encrypt| C
K -.-> |same key used to decrypt| P2
# Chapter 2 -- Illustration: symmetric encryption (one shared key)
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
from matplotlib.patches import FancyArrowPatch, FancyBboxPatch
fig, ax = plt.subplots(figsize=(9, 3.2))
def box(x, label, color):
ax.add_patch(FancyBboxPatch((x, 0.9), 1.6, 0.8, boxstyle="round,pad=0.05",
facecolor=color, edgecolor="black"))
ax.text(x+0.8, 1.3, label, ha="center", va="center", fontsize=9)
box(0.2, "Plaintext", "#d6eaf8"); box(3.0, "Encrypt", "#aed6f1")
box(5.8, "Ciphertext", "#f5b7b1"); box(8.6, "Decrypt", "#aed6f1")
box(11.4, "Plaintext", "#d6eaf8")
for x0 in (1.8, 4.6, 7.4, 10.2):
ax.add_patch(FancyArrowPatch((x0, 1.3), (x0+1.2, 1.3), arrowstyle="->", mutation_scale=16))
# same key feeding both encrypt and decrypt
ax.text(3.8, 2.6, "SHARED SECRET KEY", ha="center", fontsize=9, fontweight="bold", color="#b9770e")
ax.add_patch(FancyArrowPatch((3.8, 2.5), (3.8, 1.75), arrowstyle="->", mutation_scale=14, color="#b9770e"))
ax.add_patch(FancyArrowPatch((3.8, 2.5), (9.4, 1.75), arrowstyle="->", mutation_scale=14, color="#b9770e"))
ax.text(6.5, 0.4, "Same key encrypts and decrypts (e.g., AES-GCM, ChaCha20). Fast; key distribution is the challenge.",
ha="center", fontsize=8, style="italic")
ax.set_xlim(0, 13.2); ax.set_ylim(0, 3); ax.axis("off")
ax.set_title("Symmetric Encryption")
plt.tight_layout(); plt.savefig("ch02_symmetric.png", dpi=110)
print("Saved ch02_symmetric.png")
The Feistel Network: A Blueprint for Block Ciphers#
Most classic block ciphers are not built as a single monolithic permutation but from a repeated structure called a Feistel network, named for Horst Feistel, who developed it at IBM for the Lucifer cipher that became the Data Encryption Standard (DES). A Feistel network is elegant because it turns any round function F, which need not itself be invertible, into an invertible cipher. The block is split into a left half L and a right half R, and each round computes a new pair from a round key k_i:
Decryption runs the identical structure with the round keys reversed, because the XOR is self-inverting and the swapped halves let each step be undone without ever inverting F. This is why designers can pour all their cryptographic strength into a strong, non-linear, hard-to-invert F and still obtain a cipher that decrypts cleanly. DES uses sixteen Feistel rounds; later designs such as Blowfish, Twofish, and Camellia are Feistel or Feistel-like, while AES instead uses a non-Feistel substitution-permutation network. The Feistel idea also underlies the format-preserving and tweakable constructions met later, so it is worth recognizing on sight.
flowchart TB
A["L(i-1)"] --> X["XOR"]
B["R(i-1)"] --> F["F(R, k_i)"]
F --> X
B --> LO["L(i) = R(i-1)"]
X --> RO["R(i) = L(i-1) XOR F(R(i-1), k_i)"]
2.6 Block Cipher Modes of Operation#
A block cipher by itself only transforms a single block, which is almost never what we need. How we stitch many blocks together, the mode of operation, turns out to matter as much as the cipher, and is where security is most often quietly lost.
A block cipher encrypts exactly one block. A mode of operation specifies how to use the cipher repeatedly to encrypt a message longer than one block, and this seemingly mechanical choice has enormous security consequences.
The naive approach is Electronic Codebook (ECB) mode: split the plaintext into blocks and encrypt each independently with the same key. ECB is simple and parallelizable, and it is also broken, because identical plaintext blocks produce identical ciphertext blocks. The result leaks the structure of the data. The famous demonstration encrypts a bitmap image of the Linux penguin in ECB mode: the outline of the penguin remains plainly visible in the ciphertext, because regions of identical color encrypt to identical patterns. Never use ECB for data with any structure, which is essentially all real data.
Secure modes break this pattern by chaining or randomizing each block. Cipher Block Chaining (CBC) XORs each plaintext block with the previous ciphertext block before encrypting, and uses a random initialization vector (IV) for the first block, so identical plaintexts encrypt differently each time. CBC requires padding and is sequential for encryption. Cipher Feedback (CFB) and Output Feedback (OFB) turn a block cipher into a stream cipher. Counter (CTR) mode encrypts an incrementing counter to produce a keystream that is XORed with the plaintext; it is parallelizable, needs no padding, and is widely preferred, but it is fatally insecure if a counter/nonce value is ever reused with the same key.
Crucially, all of the modes above provide confidentiality only. They do not detect tampering: an attacker can flip bits in the ciphertext and cause predictable changes in the decrypted plaintext. This gap is closed by Galois/Counter Mode (GCM), an authenticated encryption mode that combines CTR-mode confidentiality with a built-in authentication tag, so any modification is detected on decryption. AES-GCM and the stream-cipher construction ChaCha20-Poly1305 are the modern defaults; they belong to the AEAD family discussed in Section 2.8. The code cell below makes ECB’s failure visible by encrypting a simple patterned image in ECB and CBC modes.
A practical note ties these modes to engineering reality. CTR and GCM are parallelizable and require no padding, which suits high-throughput systems and is one reason AES-GCM dominates TLS; CBC is sequential and needs padding, which historically exposed it to padding-oracle attacks. All modes that take an IV or nonce demand care: the IV for CBC must be unpredictable, while the nonce for CTR and GCM must be unique but need not be secret, and confusing these requirements has broken real systems. The single most important operational rule across every mode is the one stated for the one-time pad and repeated for GCM: the combination of key and nonce must never repeat. When this discipline is hard to guarantee, for example across distributed servers, prefer a nonce-misuse-resistant mode such as AES-GCM-SIV, which degrades gracefully if a nonce is accidentally reused.
# Chapter 2 -- ECB vs CBC: why ECB leaks structure (self-contained)
import os
import numpy as np
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
from cryptography.hazmat.primitives.ciphers import Cipher, algorithms, modes
from cryptography.hazmat.primitives import padding
# Build a simple structured image (large blocks of constant color)
H = W = 128
img = np.zeros((H, W), dtype=np.uint8)
img[20:108, 20:60] = 200 # a bright rectangle
img[40:90, 70:108] = 120 # a mid-gray rectangle
raw = img.tobytes()
key, iv = os.urandom(16), os.urandom(16)
def aes_encrypt(data, mode):
padder = padding.PKCS7(128).padder()
padded = padder.update(data) + padder.finalize()
enc = Cipher(algorithms.AES(key), mode).encryptor()
return enc.update(padded) + enc.finalize()
ecb = aes_encrypt(raw, modes.ECB())[:H*W]
cbc = aes_encrypt(raw, modes.CBC(iv))[:H*W]
ecb_img = np.frombuffer(ecb, dtype=np.uint8).reshape(H, W)
cbc_img = np.frombuffer(cbc, dtype=np.uint8).reshape(H, W)
fig, ax = plt.subplots(1, 3, figsize=(11, 4))
for a, im, t in zip(ax, [img, ecb_img, cbc_img],
["Original", "AES-ECB (structure leaks!)", "AES-CBC (looks random)"]):
a.imshow(im, cmap="gray"); a.set_title(t); a.axis("off")
plt.tight_layout(); plt.savefig("ch02_ecb_vs_cbc.png", dpi=110)
print("Saved ch02_ecb_vs_cbc.png")
print("Note how the ECB ciphertext preserves the rectangles, while CBC does not.")

AES Modes in Code: ECB versus CTR#
The mode of operation (Section 2.6) is selected by a single string in most crypto libraries, and that string is
where security is won or lost. In Java’s JCE, "AES/ECB/PKCS5Padding" and "AES/CTR/NoPadding" differ by a
word, but ECB leaks structure (identical plaintext blocks produce identical ciphertext blocks, the “penguin”
problem) while CTR turns the block cipher into a keystream and requires a unique IV/nonce per message.
// AES_ECB.java -- INSECURE pattern: deterministic, no IV, leaks block structure
Cipher cipher = Cipher.getInstance("AES/ECB/PKCS5Padding");
cipher.init(Cipher.ENCRYPT_MODE, secretKey);
return Base64.getEncoder().encodeToString(cipher.doFinal(plaintext.getBytes("UTF-8")));
// AES_CTR.java -- needs a fresh random nonce/IV each message
SecureRandom secureRandom = new SecureRandom();
byte[] nonce = new byte[96/8]; secureRandom.nextBytes(nonce); // 96-bit nonce
byte[] iv = new byte[128/8]; System.arraycopy(nonce, 0, iv, 0, nonce.length);
Cipher cipher = Cipher.getInstance("AES/CTR/NoPadding");
cipher.init(Cipher.ENCRYPT_MODE, secretKey, new IvParameterSpec(iv));
Warning: two real flaws in this teaching code
The reference programs above are deliberately simple and contain two mistakes you should be able to spot after this chapter. First, both derive the AES key by SHA-1 hashing a passphrase and truncating to 16 bytes, which is not a password-based KDF (use PBKDF2/scrypt/Argon2, Section 2.9). Second, neither provides integrity: CTR without a MAC is malleable (Section 2.8), so production code should use an AEAD mode such as AES-GCM. They illustrate the mechanics of modes, not a secure design.
Because a mode’s cost also matters, the companion SymmetricKeyTest.java is a small benchmark harness: it
takes the algorithm, key size, mode, and iteration count on the command line, generates a key and (for
CBC/CTR) a random IV, and times encryption and decryption, the kind of cryptographic benchmarking discussed
in Section 2.20 and Chapter 17.
// SymmetricKeyTest.java -- time a chosen cipher/mode over N iterations
Cipher cipher = Cipher.getInstance(alg + "/" + mode + "/PKCS5Padding");
KeyGenerator keyGen = KeyGenerator.getInstance(alg); keyGen.init(keySize);
Key key = keyGen.generateKey();
byte[] iv = new byte[cipher.getBlockSize()]; new SecureRandom().nextBytes(iv);
// loop: init ENCRYPT/DECRYPT (with IvParameterSpec unless ECB), doFinal, accumulate System.nanoTime() deltas
2.7 Cryptographic Hash Functions#
So far we have pursued confidentiality. But security also demands knowing that data has not changed, and that requires a different primitive entirely. Hash functions give us a compact fingerprint of data, the foundation for integrity, signatures, and much more.
A cryptographic hash function takes an input of any size and produces a fixed-size output called a digest or hash. Examples include SHA-256 (a 256-bit digest from the SHA-2 family) and SHA-3. Hashes are everywhere: they verify file integrity, index data, store passwords (with the extra steps in Section 2.9), underpin digital signatures, and form the backbone of blockchains. A function suitable for cryptography must satisfy three security properties.
Preimage resistance (one-wayness): given a digest h, it is computationally infeasible to find any input m such that hash(m) = h. You cannot run the function backward. Second-preimage resistance: given a specific input m1, it is infeasible to find a different input m2 with the same digest. Collision resistance: it is infeasible to find any two distinct inputs with the same digest. Collisions must exist mathematically, because infinitely many inputs map to finitely many digests, but a good hash makes finding them infeasible. A related requirement is the avalanche effect: changing a single input bit should change roughly half the output bits, so digests of similar inputs look totally unrelated.
The security of collision resistance is bounded by the birthday paradox: because of the probabilistic ease of finding some matching pair, an attacker needs only about 2 to the n/2 work to find a collision in an n-bit hash, not 2 to the n. This is why a 256-bit hash offers only about 128 bits of collision security, and why digest sizes are chosen generously. History shows the stakes: MD5 and SHA-1 were once standard but are now broken for collision resistance (practical MD5 collisions were demonstrated by Xiaoyun Wang and Hongbo Yu in 2004-2005, and researchers produced a full SHA-1 collision in 2017), so neither may be used where collision resistance matters, such as certificates or signatures. Use SHA-256 or stronger today.
Most classical hashes (MD5, SHA-1, SHA-2) are built with the Merkle-Damgard construction, which
processes the message in fixed-size blocks through a compression function. This design has a quirk, the
length-extension attack, in which an attacker who knows hash(m) can compute hash(m || extra) without
knowing m, which is why naive hash(secret || message) must never be used as a MAC; HMAC (Section 2.8)
fixes this. SHA-3 uses a different sponge construction that is immune to length extension. A related
structure, the Merkle tree, hashes data in a tree so that any single item can be verified against a
small root hash, a technique central to Git, certificate transparency, and blockchains. The code cell
demonstrates the avalanche effect and a simple integrity check.
Because they are fast, deterministic, and collision-resistant, hash functions appear far beyond integrity checking, and recognizing these uses helps connect later chapters. They enable deduplication and content addressing (Git names every object by its SHA hash, so identical content is stored once and any tampering is detectable). They provide commitment: publishing the hash of a value lets you reveal the value later and prove you had not changed it, the basis of many protocols. They drive proof of work in blockchains, where miners search for inputs whose hash meets a difficulty target. They support password-adjacent uses such as deriving lookup keys and HMAC-based one-time passwords. And the Merkle tree structure, by letting any single leaf be verified against a tiny root hash with a short “proof path,” underpins Certificate Transparency, peer-to-peer file distribution, and the tamper-evident ledgers of distributed systems. When you meet these mechanisms in later chapters, remember that a single primitive, the cryptographic hash, is doing the heavy lifting.
# Chapter 2 -- Hash functions: avalanche effect and integrity check
import hashlib
def sha256(s): return hashlib.sha256(s.encode()).hexdigest()
a = sha256("The quick brown fox")
b = sha256("The quick brown fox.") # one extra character
print("SHA-256('...fox') :", a)
print("SHA-256('...fox.'):", b)
# Hamming distance between the two digests (in bits)
xa, xb = int(a,16), int(b,16)
print("Bits changed by a 1-char edit:", bin(xa ^ xb).count("1"), "of 256 (avalanche)\\n")
# Integrity verification: detect tampering
message = "Transfer $100 to Alice"
digest = sha256(message)
received = "Transfer $900 to Alice" # attacker altered the amount
print("Stored digest :", digest)
print("Recomputed match:", sha256(received) == digest, "=> tampering detected")
# Compare digest sizes / algorithms
for algo in ["md5", "sha1", "sha256", "sha3_256"]:
h = hashlib.new(algo); h.update(b"hello")
print(f" {algo:9s} ({h.digest_size*8:3d} bits): {h.hexdigest()[:32]}...")
SHA-256('...fox') : 5cac4f980fedc3d3f1f99b4be3472c9b30d56523e632d151237ec9309048bda9
SHA-256('...fox.'): 42e25dd386eb55b56db34af535fab5231db8cf1b588af95bc9c32ef849507fc5
Bits changed by a 1-char edit: 127 of 256 (avalanche)\n
Stored digest : 76aecfa667ee3b408c6cb64eaeca752a910330b17bc22981e77b86fcd914be7b
Recomputed match: False => tampering detected
md5 (128 bits): 5d41402abc4b2a76b9719d911017c592...
sha1 (160 bits): aaf4c61ddcc5e8a2dabede0f3b482cd9...
sha256 (256 bits): 2cf24dba5fb0a30e26e83b2ac5b9e29e...
sha3_256 (256 bits): 3338be694f50c5f338814986cdf06864...
The Merkle-Damgard Construction#
Just as block ciphers have a standard skeleton, classical hash functions share one called the Merkle-Damgard construction (independently by Ralph Merkle and Ivan Damgard, 1989). It builds a hash that accepts arbitrarily long input from a fixed-size compression function f that maps a chaining value plus a message block to a new chaining value. The message is padded (crucially including its length, the “Merkle-Damgard strengthening”) and split into blocks; starting from a fixed initialization vector, each block is absorbed in turn, and the final chaining value is the digest:
Merkle and Damgard proved the construction’s central virtue: if the compression function f is collision-resistant, the whole hash is collision-resistant, reducing the security of an arbitrary-length hash to that of one small primitive. MD5, SHA-1, and SHA-2 all follow this design. It has one famous wart, the length-extension attack: because the digest is the final internal state, an attacker who knows H(m) (and the length of m) can compute H(m || padding || m’) without knowing m, which is exactly why a raw Merkle-Damgard hash must never be used as a MAC by simple prefixing and why HMAC (Section 2.8) or a sponge-based hash like SHA-3, which is not Merkle-Damgard, is used instead.
Hashing in Code, and Why a CRC Is Not a Hash#
Computing a cryptographic digest in Java is a few lines via MessageDigest. The reference Hash.java shows
both MD5 (broken, shown only for illustration) and SHA-256.
// Hash.java -- SHA-256 digest of an input string
MessageDigest md = MessageDigest.getInstance("SHA-256");
byte[] digest = md.digest(input.getBytes(StandardCharsets.UTF_8)); // 32 bytes
// (the same code with "MD5" computes a broken 128-bit digest -- do not use MD5 for security)
A frequent confusion is between a cryptographic hash and a cyclic redundancy check (CRC). A CRC is an error-detection code: it catches accidental, random corruption in transmission or storage, but it is not secure, because an attacker can deliberately alter data and recompute a matching CRC. The library version is trivial,
// LibCRC.java -- CRC32 checksum (error detection only, NOT security)
CRC32 crc = new CRC32(); crc.update(input.getBytes());
System.out.println(crc.getValue());
and the companion MyCRC.java implements the underlying algorithm by hand as polynomial long division over
GF(2): it appends zero bits, repeatedly XORs the data against the divisor (generator polynomial), and the
remainder is the CRC; the receiver re-divides and a nonzero remainder signals an error. The lesson for this
chapter is the boundary it draws: use a CRC for integrity against noise, but a cryptographic hash or, better,
a MAC (next section) for integrity against an adversary.
Error Detection versus Error Correction: CRC and Hamming Codes#
The CRC above only detects accidental errors; a Hamming code goes further and corrects a single-bit
error, which is worth contrasting because it clarifies what integrity codes do and do not provide. A Hamming
code interleaves parity bits among the data bits so that, on reception, recomputing the parities yields a
syndrome that points to the exact bit position in error. The companion Hamming.cpp encodes four data bits
into seven using three even-parity bits:
// Hamming.cpp -- (7,4) Hamming code: parity bits computed by XOR over data positions
data[6] = data[0] ^ data[2] ^ data[4]; // parity p3
data[5] = data[0] ^ data[1] ^ data[4]; // parity p2
data[3] = data[0] ^ data[1] ^ data[2]; // parity p1
// on receive, three check equations form a syndrome that locates a single flipped bit
c1 = r[6]^r[4]^r[2]^r[0]; c2 = r[5]^r[4]^r[1]^r[0]; c3 = r[3]^r[2]^r[1]^r[0];
The crucial security caveat is identical to the one for CRC (Section 2.7): Hamming codes and CRCs defend against random noise, not against an adversary, who can recompute any such code after tampering. Coding theory protects integrity on a noisy channel; cryptographic MACs and signatures protect integrity against a malicious one. The two solve different problems and must not be confused.
2.8 Message Authentication Codes and Authenticated Encryption#
A hash alone proves a message is unchanged only if the digest itself cannot be forged, which fails the moment an attacker can recompute it. Adding a secret key closes that gap and lets us guarantee integrity and authenticity (confidentiality, when needed, comes from encryption, not from the MAC itself).
Encryption hides data but, as we saw, most modes do not detect tampering. Integrity and authentication are provided by a message authentication code (MAC): a short tag computed from the message and a shared secret key. The sender transmits the message and tag; the receiver recomputes the tag with the same key and accepts only if it matches. Because the attacker lacks the key, they cannot forge a valid tag for a modified message. A MAC thus proves both that the message is unchanged (integrity) and that it came from someone holding the key (authentication), though, unlike a signature, it does not provide non-repudiation, since either party could have produced the tag.
The standard MAC is HMAC (hash-based MAC), which wraps a hash function in a specific keyed
construction, HMAC(K, m) = H((K xor opad) || H((K xor ipad) || m)). This nested design makes HMAC
secure even when built on a Merkle-Damgard hash, immunizing it against the length-extension attack that
dooms naive H(K || m). HMAC-SHA256 is ubiquitous in APIs, tokens, and protocols.
Combining encryption and a MAC correctly is subtle, and doing it by hand invites mistakes (the order matters; encrypt-then-MAC is the safe composition). The modern solution is authenticated encryption with associated data (AEAD), which provides confidentiality, integrity, and authentication in a single primitive, and also authenticates associated data (such as packet headers) that must be visible but unmodified. The two dominant AEAD constructions are AES-GCM and ChaCha20-Poly1305; both are used in TLS 1.3. The non-negotiable rule for AEAD is never reuse a nonce with the same key: nonce reuse in GCM not only leaks plaintext relationships but can expose the authentication key itself, enabling forgeries. When in doubt, prefer a misuse-resistant AEAD or a library that manages nonces for you.
Going Deeper (graduate/research): security definitions
The relevant security notion for authenticated encryption is indistinguishability under chosen- ciphertext attack (IND-CCA) combined with ciphertext integrity (INT-CTXT); together these imply authenticated-encryption security (AE). A scheme that is IND-CPA only (like raw CBC) succumbs to chosen-ciphertext attacks such as the padding oracle attack, where the error behavior of a decryptor leaks one plaintext byte at a time. The padding-oracle attack (Vaudenay, 2002) broke many real CBC deployments and is the practical reason the field moved decisively to AEAD. The lesson is definitional: choosing the right security goal (AE/IND-CCA, not merely confidentiality) is as important as choosing a strong cipher.
A subtle but important question is composition order when building authenticated encryption from separate encryption and MAC primitives, a topic that has caused real vulnerabilities. There are three options: Encrypt-and-MAC (MAC the plaintext, used by SSH), MAC-then-Encrypt (MAC the plaintext, then encrypt both, used by older TLS), and Encrypt-then-MAC (encrypt, then MAC the ciphertext, used by IPsec). Cryptographers showed that only Encrypt-then-MAC is generically secure, because it lets the receiver verify integrity before doing any decryption, so malformed ciphertexts are rejected without ever exposing decryption behavior to the attacker, which is exactly what defeats padding-oracle attacks. This is one more reason to prefer a vetted AEAD construction that gets the composition right internally rather than assembling encryption and MAC by hand. It also illustrates a meta-lesson of the chapter: the details of how primitives are combined are themselves security-critical, not mere engineering trivia.
Hash, MAC, and Digital Signature Compared#
A frequent and consequential misconception deserves to be confronted directly: a hash by itself does not provide integrity against a deliberate attacker. If a message travels with a plain hash of itself, an active attacker who can modify the message in transit can simply recompute the hash of the altered message and attach it, and the recipient, recomputing the hash, finds a perfect match. The plain hash detects accidental corruption (a flipped bit from a noisy link) but not malicious tampering, because nothing about the hash is secret. Integrity against an adversary requires binding the data to a secret (a key) or to an identity (a key pair), which is exactly what a MAC and a digital signature add.
The three primitives form a ladder of guarantees. A hash maps data to a fixed digest using no key; it gives integrity only against accidental change. A MAC computes a tag using a shared secret key, so an attacker without the key cannot forge a valid tag; it provides integrity and authentication, but because both parties share the key, it cannot prove which party produced the tag, so it offers no non-repudiation. A digital signature uses the signer’s private key, verifiable by anyone with the corresponding public key; it provides integrity, authentication, and non-repudiation, since only the private-key holder could have produced the signature. The table and diagram make the distinctions precise.
Property |
Hash |
MAC |
Digital Signature |
|---|---|---|---|
Key used |
none |
shared secret key |
private key (verify with public key) |
Integrity (accidental) |
yes |
yes |
yes |
Integrity (malicious) |
no (attacker recomputes) |
yes |
yes |
Authentication (origin) |
no |
yes (holder of shared key) |
yes (specific signer) |
Non-repudiation |
no |
no (either party could forge) |
yes |
Typical algorithms |
SHA-256, SHA-3, BLAKE2 |
HMAC, CMAC, Poly1305 |
RSA-PSS, ECDSA, EdDSA |
Example use |
file checksum, dedup |
API request authentication |
code signing, certificates, contracts |
graph TD
subgraph Hash [Hash: no key]
H1[message] --> H2[hash fn] --> H3[digest]
end
subgraph MAC [MAC: shared secret key]
M1[message + shared key] --> M2[HMAC] --> M3[tag: integrity + auth]
end
subgraph DS [Digital Signature: key pair]
D1[message + signer PRIVATE key] --> D2[sign] --> D3[signature]
D3 --> D4[verify with signer PUBLIC key: integrity + auth + non-repudiation]
end
The practical rule follows directly: use a plain hash only for non-adversarial integrity (detecting corruption or deduplicating); use a MAC when two parties share a key and need to verify that messages between them are authentic and unmodified; and use a digital signature when verification must be public or when non-repudiation is required, as in software updates, TLS certificates, and signed documents. This is also why the authenticated encryption of the previous pages pairs encryption with a MAC or signature rather than a bare hash.
Wrong-Key Behavior: Garbage Output versus Null Rejection#
A subtle but important question, and the subject of a focused comparative study, is what a cipher actually does when you decrypt with the wrong key (or feed it tampered ciphertext). The answer is not the same for all schemes, and the difference has real security consequences. Broadly, a scheme reacts in one of two ways: it produces garbage output (it silently returns plaintext-length data that happens to be wrong, with no error), or it performs null rejection (it explicitly refuses, returning nothing or raising an error because an integrity check failed). The author’s paper Which Cipher Is More Secure? A Comparative Analysis of Garbage Output and Null Rejection Behavior on Incorrect Decryption examines this behavior across ciphers and modes in detail; this section develops the underlying principles.
The behavior depends on the mode and on whether integrity is built in. Stream ciphers and the unauthenticated block-cipher modes (Counter, Cipher Feedback, Output Feedback, and raw ECB or CBC on full blocks) simply exclusive-or or transform the data, so a wrong key yields garbage: pseudo-random bytes the same length as the plaintext, with no signal that anything went wrong. CBC or ECB with PKCS#7 padding adds a probabilistic twist: after decrypting with the wrong key, the final block’s padding is valid only about one time in 256, so roughly 255 of 256 wrong keys trigger a padding error while about 1 in 256 slips through as garbage, exactly the behavior that, when exposed to an attacker as an oracle, enables the padding-oracle attack of Section 2.8. Authenticated encryption (AEAD) such as AES-GCM and ChaCha20-Poly1305 verifies a cryptographic tag before releasing any plaintext, so a wrong key (or any tampering) fails the tag check with overwhelming probability and the scheme performs clean null rejection, returning an authentication error and no plaintext at all. The figure summarizes these paths.
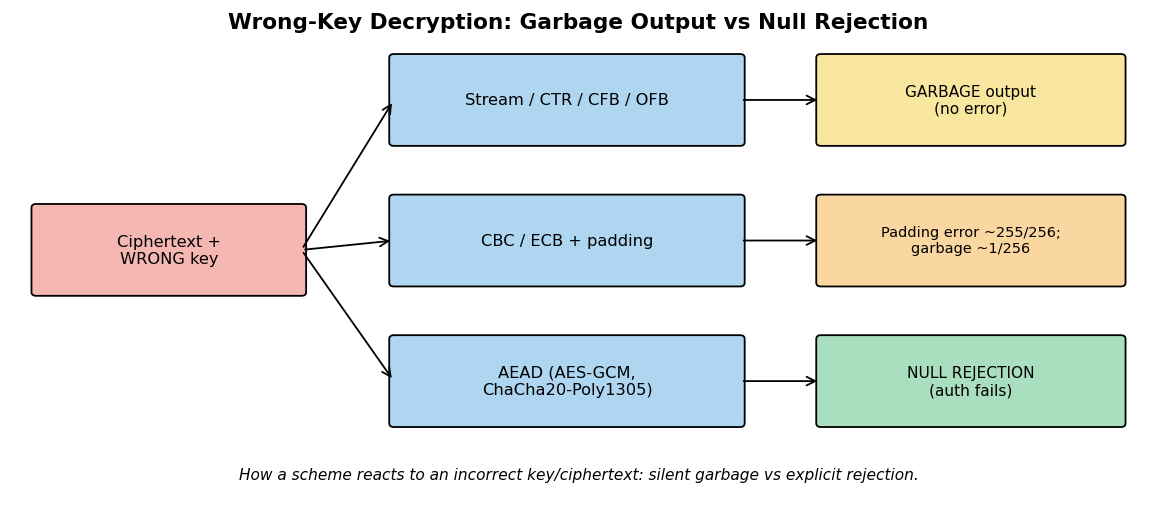
Which behavior is “more secure” depends on the threat model, which is precisely why the question is worth analyzing rather than answering glibly. Garbage output leaks nothing about correctness from the cipher itself, so an attacker brute-forcing keys gets no help from the algorithm and must instead recognize valid plaintext by its structure (a point that connects to the brute-force and known-plaintext attacks of Section 2.17); however, garbage output provides no integrity, so an attacker can tamper with ciphertext and the victim will unknowingly process corrupted data. Null rejection via authenticated encryption provides integrity and authentication, detecting both wrong keys and tampering, and, crucially, it is not an exploitable oracle the way padding rejection is, because an attacker cannot forge a valid tag in the first place. The dangerous middle case is padding-based rejection without authentication, whose one-bit correct/incorrect leakage is the basis of padding-oracle attacks. The practical conclusion aligns with the chapter’s repeated guidance: prefer authenticated encryption, so that incorrect decryption fails safely and explicitly, rather than relying on unauthenticated modes whose silent garbage offers no integrity and whose padding checks can leak. The code cell demonstrates all three behaviors on the same wrong key.
# Chapter 2 -- Wrong-key decryption: garbage output vs padding error vs null rejection (AEAD)
import os
from cryptography.hazmat.primitives.ciphers import Cipher, algorithms, modes
from cryptography.hazmat.primitives import padding
from cryptography.hazmat.primitives.ciphers.aead import AESGCM
msg = b"Attack at dawn. Meet at the old bridge by the river."
right = os.urandom(32); wrong = os.urandom(32); iv = os.urandom(16)
# (1) CTR mode: wrong key -> GARBAGE, no error
enc = Cipher(algorithms.AES(right), modes.CTR(iv)).encryptor()
ct = enc.update(msg) + enc.finalize()
dec = Cipher(algorithms.AES(wrong), modes.CTR(iv)).decryptor()
garbage = dec.update(ct) + dec.finalize()
print("(1) CTR wrong-key output:", garbage[:24], "... -> GARBAGE (no error)")
# (2) CBC + PKCS7: wrong key -> usually padding error (~255/256), rarely garbage
p = padding.PKCS7(128).padder(); padded = p.update(msg) + p.finalize()
enc = Cipher(algorithms.AES(right), modes.CBC(iv)).encryptor()
ct2 = enc.update(padded) + enc.finalize()
dec = Cipher(algorithms.AES(wrong), modes.CBC(iv)).decryptor()
raw = dec.update(ct2) + dec.finalize()
try:
unp = padding.PKCS7(128).unpadder(); unp.update(raw); unp.finalize()
print("(2) CBC wrong-key: padding happened to be valid -> GARBAGE (~1/256 case)")
except ValueError:
print("(2) CBC wrong-key: -> PADDING ERROR (the ~255/256 case)")
# (3) AES-GCM (AEAD): wrong key -> NULL REJECTION (authentication fails)
n = os.urandom(12)
ct3 = AESGCM(right).encrypt(n, msg, None)
try:
AESGCM(wrong).decrypt(n, ct3, None)
print("(3) GCM wrong-key: decrypted?! (should never happen)")
except Exception as e:
print("(3) GCM wrong-key: ->", type(e).__name__, "= NULL REJECTION (no plaintext released)")
print("\nTakeaway: AEAD fails safely (rejects); unauthenticated modes emit garbage with no integrity.")
(1) CTR wrong-key output: b'8Xz\x99\xdc\xeb@vL9k9>s\x8b\x91Y\xabO\xf6$\x04x\x8f' ... -> GARBAGE (no error)
(2) CBC wrong-key: -> PADDING ERROR (the ~255/256 case)
(3) GCM wrong-key: -> InvalidTag = NULL REJECTION (no plaintext released)
Takeaway: AEAD fails safely (rejects); unauthenticated modes emit garbage with no integrity.
The Three-Behavior Hierarchy of Incorrect Decryption#
Having seen, in the previous subsection, that a scheme can react to a wrong key with either garbage or an explicit rejection, we can now sharpen the analysis. The naive framing pits “garbage output” against “null rejection” as if they were two competing answers to a single question. They are not. As the author’s study Which Cipher Is More Secure? argues, the binary framing is malformed: the real distinction is among three operationally distinct system behaviors, which modern cryptographic engineering ranks unambiguously.
Raw primitive, no integrity check, exposed directly. A block or stream cipher used in an unauthenticated mode (CTR, CFB, OFB, raw CBC) mathematically produces noise on a wrong key. Used in isolation, with nothing downstream reacting to the bytes, it resists passive attack. This is a building block, never a complete construction.
Raw primitive wrapped by an authenticated construction that returns a single uniform failure. This is authenticated encryption (AEAD). On any deviation, the caller receives one indistinguishable error. This is the gold standard.
Raw primitive whose output is then inspected by application logic that emits structured errors on malformed plaintext. Decrypt, then check padding, parse JSON, validate a header, and report what went wrong. This third behavior is the source of nearly every real-world break of a deployed cipher in the last twenty-five years.
The ranking is not a matter of taste. It follows directly from whether each construction admits a decryption oracle, and whether that oracle, if present, leaks plaintext-dependent information. The middle option is best practice; the first is acceptable only as a primitive; the third is broken by design.
The Decryption Oracle: the Concept That Unifies the Hierarchy#
The pivotal concept is the decryption oracle: any mechanism through which an attacker can submit a ciphertext they crafted and learn something about the result without learning the plaintext directly. The mechanism need not be intentional. Any observable side effect counts: an explicit error message, a difference in response time, the presence or absence of a log entry, a cache miss, or even a change in the size of a later network packet. The fundamental confidentiality goal in the presence of an active attacker is to prevent any decryption oracle from revealing information about plaintext or key. The formal name for this guarantee is indistinguishability under adaptive chosen-ciphertext attack (IND-CCA2): a scheme that meets it reveals nothing useful even when the attacker submits arbitrary ciphertexts and watches the system react to each one.
This reframes “garbage versus null” entirely. Wrong-key output that is indistinguishable from random is necessary but not sufficient for security. Every unbroken cipher already produces such output; that is the raw mathematics of a pseudorandom permutation, not a defense. The question is never whether the bytes look random but whether the system around the cipher gives the attacker any way to react to them, observe how others react, or distinguish wrong-key noise from right-key ciphertext. AEAD supplies the missing piece, a mechanism (the authentication tag) that prevents the attacker from learning anything at all about the wrong-key output, and whose user-facing behavior is the uniform failure.
Security Verdict by Behavior#
The hierarchy can be stated as a verdict table, summarizing the comparative analysis.
Wrong-key behavior |
Where it occurs |
Security verdict |
|---|---|---|
Returns random-looking garbage directly to the caller |
Raw AES-CTR, raw AES-CBC, or any unauthenticated mode used as a primitive with no integrity layer |
Better than leaking structured errors, but inadequate as a complete scheme. Becomes broken the moment any downstream component reacts observably to the plaintext. |
Returns detailed errors revealing the cause of failure |
Unauthenticated cipher followed by a parser, padding check, or structural validator that surfaces specific failures |
Dangerous. This is the architecture exploited by every padding-oracle and format-oracle attack of the past two decades. |
Returns a single uniform authentication failure in constant time |
AEAD: AES-GCM, ChaCha20-Poly1305, AES-CCM, AES-GCM-SIV, or Encrypt-then-MAC |
Best practice. IND-CCA2 secure under standard assumptions. Recommended for all new designs. |
The construction order inside an AEAD also matters, even when the external API looks identical. Encrypt-then-MAC is provably IND-CCA2 secure when its primitives are sound; MAC-then-Encrypt and Encrypt-and-MAC have known weaknesses and were the basis of attacks against TLS before version 1.3. Prefer a dedicated AEAD mode (GCM, CCM, ChaCha20-Poly1305) or Encrypt-then-MAC over a hand-assembled composition.
Constant-Time Comparison Is Mandatory#
Warning: a fast equality check can leak the tag
AEAD security depends on the tag comparison itself being constant-time. A naive byte-by-byte comparison
that returns on the first mismatching byte lets an attacker recover the correct tag one byte at a time by
measuring response times, and therefore forge messages, even when the underlying scheme is otherwise sound.
Use the dedicated routine your platform provides: hmac.compare_digest in Python,
CRYPTO_memcmp in OpenSSL, subtle.ConstantTimeCompare in Go, and crypto.timingSafeEqual in Node.js.
Hand-written tag comparison with == or memcmp is one of the most common cryptographic vulnerabilities in
deployed code.
The decision logic for a correctly engineered decryption interface is shown below.
flowchart TD
A[Ciphertext + key + nonce + associated data] --> B{Authenticated construction?}
B -- No --> C[Raw mode produces output]
C --> D{Does anything downstream<br/>react observably to plaintext?}
D -- No --> E[Resists passive attack only<br/>primitive, not a scheme]
D -- Yes --> F[Decryption oracle exists<br/>padding / format / timing leak]
F --> G[BROKEN: chosen-ciphertext attack]
B -- Yes --> H[Verify tag in constant time]
H --> I{Tag valid?}
I -- Yes --> J[Release plaintext]
I -- No --> K[Uniform failure<br/>no plaintext, no reason, constant time]
K --> L[IND-CCA2: oracle closed]
Historical Attacks That Forced the Modern Consensus#
The hierarchy was not deduced in a vacuum; it emerged from a sequence of practical attacks that showed, repeatedly, that an unauthenticated cipher paired with a format check is catastrophic against an active attacker. The same patterns still appear in newly deployed systems, which is why the history is worth knowing rather than memorizing as trivia.
Bleichenbacher’s attack on RSA PKCS#1 v1.5 (1998). The original padding oracle. A TLS server that decrypted RSA-encrypted session keys responded differently depending on whether the recovered PKCS#1 v1.5 padding was well formed. By submitting modified ciphertexts and watching which were accepted, an attacker could recover an RSA-encrypted message in roughly one million queries. The ROBOT variants (2018) found vulnerable deployments two decades later, proving how persistent the format-inspection pattern is.
Vaudenay’s padding oracle on CBC (2002). Assuming only that the recipient distinguishes ciphertexts that decrypt to well-formed PKCS#7 padding from those that do not, Vaudenay recovered the entire plaintext at about 128 queries per byte, with no knowledge of the key and against any block or key size, whenever CBC is used without authentication. This established the foundational principle: if the cipher is not authenticated, the system that uses it leaks the plaintext.
Lucky 13 (2013). AlFardan and Paterson exploited a residual timing channel in how TLS processed CBC-mode records. Even after explicit padding errors were unified, the time to compute an HMAC over a variable-length record leaked the padding position. Lucky 13 was a major impetus for deprecating CBC in TLS in favor of AEAD.
POODLE (2014). Moeller, Duong, and Kotowicz exploited SSL 3.0’s loose CBC padding (only the final length byte was checked). By forcing a victim’s browser to resend the same secret over many connections and substituting chosen ciphertext blocks, an attacker recovered one byte per 256 connections on average. POODLE accelerated the retirement of SSL 3.0.
The common pattern: in every case an unauthenticated decryption is followed by a check that distinguishes well-formed from malformed plaintext, and the result is observable. The attacker does not break the cipher; the attacker uses the system’s own integrity check as a measuring instrument and reads the plaintext off bit by bit. The defense is always the same: replace the unauthenticated mode with an authenticated one whose failure is uniform and constant-time.
The Limits of Authenticated Encryption#
AEAD solves the problem of telling valid ciphertexts from invalid ones. It does not solve every problem an active attacker can pose, and students often over-trust it. Two limits deserve explicit treatment.
Replay protection is out of scope. AEAD guarantees that any modification to ciphertext, key, nonce, or associated data fails on decryption. It does not reject an unmodified ciphertext replayed verbatim, because a captured valid ciphertext is, by definition, valid. Replay defense lives at the protocol layer: monotonic sequence numbers carried in the associated data, timestamps with bounded validity, or stateful nonce tracking. TLS 1.3 uses internal sequence numbers; QUIC uses packet numbers; the Noise framework uses a strictly increasing counter.
Nonce reuse is catastrophic. AES-GCM and ChaCha20-Poly1305 require that any (key, nonce) pair encrypt at most one message. Reuse is not graceful degradation; it is collapse. Two AES-GCM messages under the same (key, nonce) leak the XOR of the plaintexts and the authentication subkey, after which an attacker can forge arbitrary messages. The defense in conventional AEAD is operational (never repeat a nonce), which is harder than it sounds in long-lived, high-volume, or multi-process systems. Nonce-misuse-resistant AEAD such as AES-GCM-SIV (RFC 8452, 2019) degrades gracefully: on reuse an attacker learns only whether two plaintexts were identical. Use it where nonce uniqueness cannot be guaranteed, such as distributed databases or stateless tokens.
Warning: never reuse a nonce
A single nonce reuse under AES-GCM or ChaCha20-Poly1305 with the same key is enough to permit forgery of arbitrary messages. If the deployment cannot guarantee unique nonces (shared state, low-entropy random generation, fork-after-key-derivation), use AES-GCM-SIV or another nonce-misuse-resistant construction.
Practical Guidelines for Implementers#
The argument condenses into concrete engineering practice, consistent with NIST SP 800-38D, RFC 8439, RFC 8452, and the TLS 1.3 design rationale.
Use a vetted AEAD construction. AES-GCM, ChaCha20-Poly1305, AES-CCM, and AES-GCM-SIV are the standard choices. Avoid hand-rolled cipher-plus-MAC compositions.
Treat the decryption interface as two-state. Either a valid plaintext, or a single uniform failure. Never expose why decryption failed to anyone who can submit ciphertexts.
Use constant-time tag comparison from the standard library, never
==ormemcmp.Generate nonces correctly. A counter suits short-lived sessions; for long-lived or distributed deployments prefer AES-GCM-SIV with a random nonce, or a key-derivation scheme that guarantees uniqueness.
Add replay protection at the protocol layer with sequence numbers, timestamps, or nonce-tracking caches.
Do not log decryption-failure details. A log line that distinguishes a tag failure from a later parse failure is itself an oracle. Log only that authenticated decryption failed.
Design the API so misuse is hard. Wrap the primitive in an interface that handles nonce generation, tracks uniqueness, and exposes only high-level encrypt and decrypt. The libsodium
crypto_secretboxAPI is a model.
Knowledge Check
Why is “wrong-key output looks random” necessary but not sufficient for confidentiality against an active attacker?
A service returns “bad padding” for one class of failures and “decryption error” for another. Name the attack class this enables and the single design change that closes it.
Why does AEAD not, by itself, stop a replay attack, and where must replay defense live?
Answers: (1) Random-looking output still loses if any downstream behavior lets the attacker react to it; the missing piece is integrity plus a uniform failure (an AEAD tag), which closes the decryption oracle. (2) A padding-/format-oracle (adaptive chosen-ciphertext) attack; switch to authenticated encryption with a single constant-time uniform failure. (3) A replayed valid ciphertext is genuinely valid, so the tag passes; replay defense belongs to the protocol layer via sequence numbers, timestamps, or nonce tracking.
In-Class Exercise: bit-flipping AES-CTR versus AES-GCM
Encrypt the message transfer 100 USD to bob with AES-CTR under a random key and nonce. Acting as an
attacker without the key, XOR 100 USD to bob with 999 USD to eve to build a delta mask, apply it to the
ciphertext at the matching offset, and decrypt: the plaintext now reads transfer 999 USD to eve, accepted
with no detection. This demonstrates that CTR is fully malleable. Now repeat with AES-GCM using the same
key and nonce: the modified ciphertext fails authentication and decryption returns a uniform error with no
plaintext. Finally repeat against AES-CBC and observe partial malleability (you control the target block
only by randomizing the previous one). Write one paragraph explaining why CTR is fully malleable, CBC
partially, and GCM non-malleable. This exercise adapts Exercise A.2 of Which Cipher Is More Secure?
Going Deeper (graduate/research): three labs from the source study
The author’s reference document specifies three companion laboratories suitable for an advanced course, each
mapping to one row of the hierarchy: (A.1) Padding oracle to authenticated encryption, building a CBC
server with distinguishable padding/format errors, recovering a plaintext byte at roughly 128 queries per
byte, then collapsing the errors and finally swapping in AES-GCM to watch the attack die; (A.2)
Bit-flipping on AES-CTR (the malleability exercise above, with a GCM negative control); and (A.3) Timing
attack on naive tag comparison, recovering a tag at about 256 x tag_length queries against an
early-return comparator, then fixing it with hmac.compare_digest and confirming the per-byte signal
vanishes. Lab A.3 is the laboratory analogue of the Lucky 13 attack.
The single rule to carry forward: a wrong key should produce indistinguishable noise inside the cipher and a uniform failure outside it. Both halves are mandatory. Any deployed decryption interface that distinguishes between failure modes, through return values, exception types, log entries, or response timing, should be treated as a candidate for a chosen-ciphertext attack until proven otherwise. With message integrity and authenticated encryption now firmly in hand, we turn next to how keys themselves are derived and stored.
Computing an HMAC in Code#
The MAC of this section is just as accessible in code. Java’s Mac class with "HmacSHA256" keys an HMAC and
authenticates a message in three calls, this is the keyed integrity that a bare hash or CRC cannot provide.
// HMAC.java -- keyed message authentication with HMAC-SHA-256
Mac mac = Mac.getInstance("HmacSHA256");
mac.init(new SecretKeySpec(secret.getBytes(), "HmacSHA256"));
byte[] tag = mac.doFinal(message.getBytes()); // verify with a constant-time compare!
As Section 2.8 stressed, the verifier must compare tags with a constant-time routine (such as
MessageDigest.isEqual in modern Java) rather than a normal byte-by-byte equality, or it reintroduces a timing
oracle.
Authenticated Encryption in Practice: Encrypt-then-MAC#
Bringing together the confidentiality of Section 2.6 and the integrity of this section, a production system
should provide authenticated encryption, and the companion cryptopp-authenc.cpp (using the Crypto++
library) is a faithful Encrypt-then-MAC reference. It derives independent keys from a password with PBKDF2
(Section 2.9), encrypts with AES-CBC, and authenticates the ciphertext with HMAC-SHA-256, so decryption first
verifies the tag and only then releases plaintext.
// cryptopp-authenc.cpp (structure) -- PBKDF2-derived keys, AES-CBC, then HMAC-SHA-256 over the ciphertext
DeriveKeyAndIV(password, salt, /*iterations*/ 100, ekey, iv, akey); // PBKDF2-HMAC-SHA512
CBC_Mode<AES>::Encryption enc; enc.SetKeyWithIV(ekey, ekey.size(), iv, iv.size());
HMAC<SHA256> hmac; hmac.SetKey(akey, akey.size());
// Encrypt-then-MAC: StreamTransformationFilter -> HashFilter(hmac) appends the tag to the ciphertext
// Decrypt: HashVerificationFilter checks the tag (THROW_EXCEPTION) BEFORE decrypting -> uniform failure
This is the concrete embodiment of the chapter’s central guidance and of the “which cipher is more secure?” analysis (Section 2.8): separate keys for encryption and authentication, the MAC computed over the ciphertext, and verification that fails closed before any plaintext is exposed. For new code, a single AEAD primitive (AES-GCM or ChaCha20-Poly1305) is preferred over a hand-assembled composition, but this example shows exactly what such a primitive does internally.
2.9 Key Derivation and Password Storage#
Keys and the passwords behind them are only as strong as how we derive and store them. Having built encryption and authentication, we now confront the very human problem of turning weak passwords into strong keys without handing attackers an easy target.
Two recurring problems require turning weak or raw key material into strong cryptographic keys: deriving keys from human passwords, and storing passwords for authentication. Both are solved by key derivation functions (KDFs), but with an important twist.
Passwords are low-entropy: people choose predictable strings, and the space of likely passwords is small enough to enumerate. If a site stored passwords in plaintext, a database breach would expose them all; if it stored a fast hash like SHA-256, an attacker with the stolen hashes could try billions of guesses per second on a GPU and crack most of them, especially with precomputed rainbow tables. The defenses are salting and key stretching. A salt is a unique random value stored alongside each hash; it ensures identical passwords produce different stored values and defeats precomputed tables. Key stretching deliberately makes the function slow and resource-intensive, so each guess costs the attacker dearly while remaining tolerable for a single legitimate login.
Password-hashing KDFs implement these ideas. PBKDF2 applies a hash thousands or millions of times; it is widely supported but only CPU-hard, so GPUs and custom hardware accelerate attacks. bcrypt is deliberately slow and somewhat memory-using. scrypt and, the current best practice, Argon2 (the 2015 Password Hashing Competition winner) are memory-hard: they require large amounts of memory, which neutralizes the parallelism advantage of GPUs and ASICs. For deriving an encryption key from a shared secret that is already high-entropy (for instance the output of a key exchange), a fast KDF such as HKDF is appropriate; HKDF is not for passwords. The practical guidance: never store passwords reversibly or with a plain fast hash; use Argon2id (or scrypt/bcrypt) with a unique salt and tuned cost parameters. The code cell contrasts an insecure approach with a correct one.
Two refinements deserve mention because they appear in practice and on examinations. A pepper is a secret value added to the password before hashing, like a salt but kept separate from the database (for example in application configuration or an HSM), so that a database breach alone does not give the attacker everything needed to start cracking. Unlike salts, a pepper is shared across users and must remain secret. The second is breach response: when a password database is exposed, the correct reaction depends on how it was stored. If passwords were stored with a strong salted, memory-hard KDF, attackers still face enormous cost per guess, buying defenders time to force resets; if they were stored with a fast hash or, worse, in plaintext, the credentials must be considered immediately compromised, including everywhere users reused them, which is why credential stuffing (replaying leaked passwords against other sites) is among the most common real-world attacks. These practices link cryptographic storage to the incident-response and identity-management chapters, where the organizational response to credential exposure is developed in full.
# Chapter 2 -- Password storage: the wrong way and a better way
import hashlib, os, hmac
password = "correct horse battery staple"
# WRONG: a single fast hash, no salt -> vulnerable to rainbow tables and fast GPU cracking
bad = hashlib.sha256(password.encode()).hexdigest()
print("INSECURE sha256(pw):", bad)
# BETTER: unique salt + key stretching (PBKDF2 shown for portability; prefer Argon2id in production)
salt = os.urandom(16)
iterations = 200_000
derived = hashlib.pbkdf2_hmac("sha256", password.encode(), salt, iterations)
print("Salt (hex) :", salt.hex())
print("PBKDF2 derived hash:", derived.hex())
# Verification at login: recompute with the stored salt and compare in constant time
def verify(candidate, salt, iterations, stored):
test = hashlib.pbkdf2_hmac("sha256", candidate.encode(), salt, iterations)
return hmac.compare_digest(test, stored) # constant-time compare avoids timing leaks
print("Login correct pw :", verify(password, salt, iterations, derived))
print("Login wrong pw :", verify("guess", salt, iterations, derived))
print("\\nProduction note: prefer argon2-cffi (Argon2id), which is memory-hard.")
INSECURE sha256(pw): c4bbcb1fbec99d65bf59d85c8cb62ee2db963f0fe106f483d9afa73bd4e39a8a
Salt (hex) : 9446a136fd85d978d1134d4c487c1c2f
PBKDF2 derived hash: efd6aa96e2910e770d84d20fed06558bffc1ae0f3b1ba82c65678cf4482a40b7
Login correct pw : True
Login wrong pw : False
\nProduction note: prefer argon2-cffi (Argon2id), which is memory-hard.
2.10 Public-Key Cryptography and RSA#
Everything so far assumed the two parties already shared a secret key, which simply relocates the problem. Public-key cryptography dissolves it, and we start with the system that made the idea concrete.
We begin where all of security ultimately bottoms out. Before any firewall or password matters, we need the mathematics that makes secrecy and trust possible at all, so this section defines what cryptography promises and, just as importantly, what it does not.
Symmetric cryptography has an inescapable bootstrapping problem: the parties must already share a secret key. In 1976 Whitfield Diffie and Martin Hellman published the idea of public-key (asymmetric) cryptography, which dissolves this problem. Each party holds a mathematically linked key pair: a public key that may be freely published, and a private key kept secret. Anyone can encrypt a message with the recipient’s public key, but only the holder of the matching private key can decrypt it. Conversely, the private key can sign data in a way that anyone can verify with the public key, giving authentication and non-repudiation. Public-key cryptography rests on trapdoor mathematical problems: operations easy to perform but infeasible to reverse without secret information.
The first and still most recognizable public-key system is RSA (Rivest, Shamir, Adleman, 1977). Its security rests on the difficulty of factoring the product of two large primes. Key generation chooses two large secret primes p and q, computes the modulus n = p*q and Euler’s totient phi = (p-1)(q-1), selects a public exponent e coprime to phi (commonly 65537), and computes the private exponent d as the modular inverse of e modulo phi. The public key is (n, e); the private key is d. Encryption of a message m is c = m^e mod n, and decryption is m = c^d mod n. The correctness follows from Euler’s theorem; the security follows from the belief that recovering d from the public (n, e) requires factoring n, which is infeasible for sufficiently large n (today at least 2048 bits, with 3072 or more recommended for long-term use). In practice RSA is never used on raw messages; secure padding (OAEP for encryption, PSS for signatures) is essential, and “textbook RSA” without padding is insecure. The code cell illustrates RSA on tiny numbers for understanding, then with a real library.
Two cautions make RSA safe in practice, and both are frequent exam and audit topics. First, textbook RSA is insecure and must never be used directly. Because plain RSA is deterministic, identical messages encrypt identically (leaking equality), small messages with a small public exponent can be recovered by simply taking an integer root (m^e may be less than n, so no modular reduction occurs), and the multiplicative homomorphism enables chosen-ciphertext manipulation. Secure padding fixes these: OAEP randomizes and structures the plaintext before encryption, and PSS does so for signatures, which is why every real library applies them. Second, RSA has been undone by parameter mistakes rather than by factoring: reusing a modulus across users, choosing primes that are too close together, using a tiny private exponent, or, as Section 2.4 noted, generating primes with poor randomness so that two keys share a common factor that a simple GCD computation reveals. These lessons reinforce the chapter’s refrain: even a sound algorithm fails when its preconditions, randomness, padding, and parameter hygiene, are violated.
In asymmetric (public-key) encryption, a message is encrypted with the recipient’s public key and can be decrypted only with their matching private key, so anyone can send a confidential message to the key-pair’s owner without sharing a secret in advance.
flowchart LR
P1[Plaintext] -->|Encrypt| C[Ciphertext]
C -->|Decrypt| P2[Plaintext]
PUB([Recipient PUBLIC key]) -.-> |encrypt| C
PRIV([Recipient PRIVATE key]) -.-> |decrypt| P2
For digital signatures the key roles are reversed: the signer uses their private key to sign, and anyone can verify with the signer’s public key, providing integrity, authenticity, and non-repudiation.
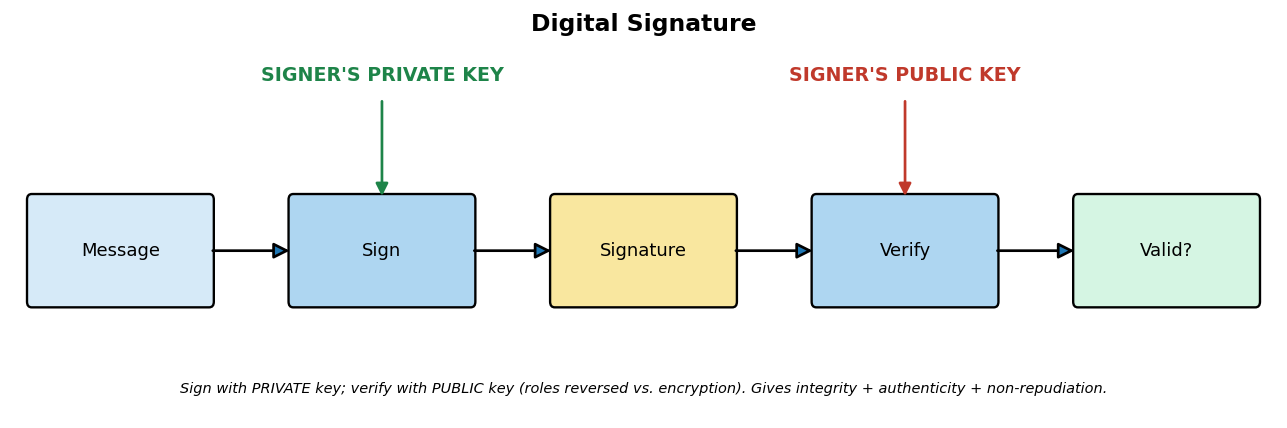
# Chapter 2 -- Illustration: asymmetric encryption and signing (key pair)
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
from matplotlib.patches import FancyArrowPatch, FancyBboxPatch
fig, ax = plt.subplots(2, 1, figsize=(9, 5.2))
def draw(a, title, k1, k2, note):
def box(x, label, color):
a.add_patch(FancyBboxPatch((x, 0.9), 1.6, 0.8, boxstyle="round,pad=0.05",
facecolor=color, edgecolor="black"))
a.text(x+0.8, 1.3, label, ha="center", va="center", fontsize=9)
box(0.2,"Plaintext","#d6eaf8"); box(3.0,"Encrypt","#aed6f1")
box(5.8,"Ciphertext","#f5b7b1"); box(8.6,"Decrypt","#aed6f1"); box(11.4,"Plaintext","#d6eaf8")
for x0 in (1.8,4.6,7.4,10.2):
a.add_patch(FancyArrowPatch((x0,1.3),(x0+1.2,1.3),arrowstyle="->",mutation_scale=16))
a.text(3.8,2.6,k1,ha="center",fontsize=9,fontweight="bold",color="#1f6f8b")
a.add_patch(FancyArrowPatch((3.8,2.5),(3.8,1.75),arrowstyle="->",mutation_scale=14,color="#1f6f8b"))
a.text(9.4,2.6,k2,ha="center",fontsize=9,fontweight="bold",color="#7d3c98")
a.add_patch(FancyArrowPatch((9.4,2.5),(9.4,1.75),arrowstyle="->",mutation_scale=14,color="#7d3c98"))
a.text(6.5,0.35,note,ha="center",fontsize=8,style="italic")
a.set_xlim(0,13.2); a.set_ylim(0,3); a.axis("off"); a.set_title(title)
draw(ax[0],"Asymmetric Encryption (confidentiality)","RECIPIENT PUBLIC KEY","RECIPIENT PRIVATE KEY",
"Anyone encrypts with the public key; only the private-key holder can decrypt.")
draw(ax[1],"Digital Signature (authenticity, integrity, non-repudiation)","SIGNER PRIVATE KEY","SIGNER PUBLIC KEY",
"Signer signs with the private key; anyone verifies with the public key. (Roles reversed vs. encryption.)")
plt.tight_layout(); plt.savefig("ch02_asymmetric.png", dpi=110)
print("Saved ch02_asymmetric.png")
# Chapter 2 -- RSA from first principles (tiny, for learning) and with a real library
# --- Educational toy RSA (DO NOT use small numbers in practice) ---
def egcd(a, b):
if b == 0: return (a, 1, 0)
g, x, y = egcd(b, a % b)
return (g, y, x - (a // b) * y)
def modinv(a, m):
g, x, _ = egcd(a, m)
return x % m
p, q = 61, 53
n = p * q
phi = (p - 1) * (q - 1)
e = 17
d = modinv(e, phi)
print(f"p={p} q={q} n={n} phi={phi} e={e} d={d}")
m = 42
c = pow(m, e, n) # encryption: c = m^e mod n
m2 = pow(c, d, n) # decryption: m = c^d mod n
print(f"message={m} cipher={c} decrypted={m2} ok={m==m2}\\n")
# --- Real RSA with OAEP padding and PSS signatures ---
from cryptography.hazmat.primitives.asymmetric import rsa, padding
from cryptography.hazmat.primitives import hashes
priv = rsa.generate_private_key(public_exponent=65537, key_size=2048)
pub = priv.public_key()
msg = b"Public-key cryptography solves key distribution."
ct = pub.encrypt(msg, padding.OAEP(mgf=padding.MGF1(hashes.SHA256()),
algorithm=hashes.SHA256(), label=None))
pt = priv.decrypt(ct, padding.OAEP(mgf=padding.MGF1(hashes.SHA256()),
algorithm=hashes.SHA256(), label=None))
print("Decrypted matches original:", pt == msg)
sig = priv.sign(msg, padding.PSS(mgf=padding.MGF1(hashes.SHA256()),
salt_length=padding.PSS.MAX_LENGTH), hashes.SHA256())
print("Signature length (bytes):", len(sig), "(verifiable with the public key)")
p=61 q=53 n=3233 phi=3120 e=17 d=2753
message=42 cipher=2557 decrypted=42 ok=True\n
Decrypted matches original: True
Signature length (bytes): 256 (verifiable with the public key)
2.11 Diffie-Hellman Key Exchange#
RSA lets us encrypt to a public key, but asymmetric operations are slow, so in practice we use them mainly to agree on a fast symmetric key. The most elegant way to do that, over a fully public channel, is the next topic.
Public-key encryption lets two strangers communicate secretly, but asymmetric operations are slow, so in practice we use them only to establish a shared symmetric key and then switch to fast symmetric encryption. The original and most elegant mechanism for agreeing on a shared secret over a public channel is the Diffie-Hellman key exchange (DHKE). Its near-magical property is that two parties can derive a common secret while an eavesdropper who sees every message exchanged still cannot compute it.
The classic construction works in modular arithmetic. The parties publicly agree on a large prime p and a generator g. Alice picks a secret a and sends A = g^a mod p; Bob picks a secret b and sends B = g^b mod p. Alice computes B^a mod p and Bob computes A^b mod p; both equal g^(ab) mod p, the shared secret. The eavesdropper sees g, p, A, and B but cannot recover the secret without solving the discrete logarithm problem, finding a from g^a mod p, which is infeasible for large p. The shared value is then fed through a KDF to produce symmetric keys.
A vital caveat: plain Diffie-Hellman provides no authentication, so it is vulnerable to a man-in-the-middle attack in which an active attacker performs separate exchanges with each party and relays traffic. DH must therefore be combined with authentication (signatures or certificates), as TLS does. A further refinement is ephemeral Diffie-Hellman (DHE, or ECDHE on elliptic curves), which uses fresh random secrets for every session. This provides forward secrecy: even if a server’s long-term private key is later stolen, past recorded sessions remain secret, because the per-session DH secrets were never stored. Forward secrecy is now a standard requirement and is mandatory in TLS 1.3.
To see why authentication is non-negotiable, trace the man-in-the-middle attack on unauthenticated Diffie-Hellman concretely. Alice sends A = g^a to Bob, but the attacker Mallory intercepts it and sends her own M = g^m to Bob; Bob replies with B = g^b, which Mallory again intercepts, sending her own value back to Alice. Now Alice has unknowingly established a shared secret g^(am) with Mallory, and Bob has established g^(bm) with Mallory, while each believes they are talking to the other. Mallory sits in the middle, decrypting, reading, and re-encrypting every message, completely transparent to both parties. Nothing in the mathematics of Diffie-Hellman detects this, because the protocol guarantees only that two parties share a secret, not which two parties. The fix, used by TLS, SSH, and Signal alike, is to authenticate the exchange: each side signs its key share, or the keys are bound to certificates or to pre-verified identities, so Mallory cannot substitute her own values without detection. This is the single most important practical lesson about key exchange and a frequent source of real vulnerabilities in custom protocols that “use Diffie-Hellman” but forget to authenticate it.
ElGamal Encryption#
Diffie-Hellman lets two parties agree on a secret, but it is not by itself an encryption scheme. The ElGamal cryptosystem (Taher ElGamal, 1985) turns the same discrete-logarithm hardness into full public-key encryption, and it is both historically important and still used today (notably as the basis of encryption in the OpenPGP standard and, in elliptic-curve form, in many protocols). Understanding it also illuminates why public-key encryption is usually randomized.
The setup reuses Diffie-Hellman’s parameters: a large prime p and a generator g. A user picks a private key x and publishes the public key h = g^x mod p (along with p and g). To encrypt a message m (an integer modulo p), the sender chooses a fresh random ephemeral value k and computes the ciphertext pair (c1, c2) = (g^k mod p, m * h^k mod p). To decrypt, the holder of x computes the shared value s = c1^x mod p (which equals g^(kx), exactly the Diffie-Hellman secret) and recovers m = c2 * s^(-1) mod p. Two properties stand out. First, ElGamal is probabilistic: because a fresh random k is used every time, the same plaintext encrypts to different ciphertexts, which is necessary for semantic security. Second, and mirroring the one-time-pad and nonce lessons of this chapter, k must be random, secret, and never reused: reusing k across two messages lets an attacker recover the ratio of the plaintexts, and a predictable k leaks the message entirely. ElGamal is also multiplicatively homomorphic, a property exploited in some privacy-preserving protocols. The worked example below implements textbook ElGamal on small numbers, and a production-grade reference using the Crypto++ library (2048-bit keys) accompanies this chapter’s materials.
# Chapter 2 -- Textbook ElGamal encryption (small numbers for learning)
import secrets
def egcd(a, b):
if b == 0: return (a, 1, 0)
g, x, y = egcd(b, a % b); return (g, y, x - (a // b) * y)
def modinv(a, m):
return egcd(a, m)[1] % m
# Public parameters (tiny prime for illustration; real systems use >=2048-bit p)
p, g = 2357, 2
# Key generation
x = secrets.randbelow(p - 3) + 2 # private key
h = pow(g, x, p) # public key component
print(f"Public key : (p={p}, g={g}, h={h}) Private key: x={x}")
# Encryption of message m
m = 2035
k = secrets.randbelow(p - 3) + 2 # fresh ephemeral key -- NEVER reuse
c1 = pow(g, k, p)
c2 = (m * pow(h, k, p)) % p
print(f"Plaintext m = {m} -> ciphertext (c1={c1}, c2={c2})")
# Decryption
s = pow(c1, x, p) # shared secret g^(kx)
m_rec = (c2 * modinv(s, p)) % p
print(f"Decrypted = {m_rec} correct = {m_rec == m}")
# Demonstrate probabilistic encryption: same m, new k -> different ciphertext
k2 = secrets.randbelow(p - 3) + 2
print("Same m, different k gives:", (pow(g,k2,p), (m*pow(h,k2,p))%p))
print("=> ElGamal is randomized; reusing k would break it (analogous to nonce reuse).")
Public key : (p=2357, g=2, h=1986) Private key: x=183
Plaintext m = 2035 -> ciphertext (c1=620, c2=728)
Decrypted = 2035 correct = True
Same m, different k gives: (1761, 744)
=> ElGamal is randomized; reusing k would break it (analogous to nonce reuse).
# Chapter 2 -- Diffie-Hellman shared-secret derivation (small numbers for clarity)
p = 0xFFFFFFFFFFFFFFFFC90FDAA22168C234C4C6628B80DC1CD1 # a (small, demo) prime
g = 2
import secrets
a = secrets.randbelow(p - 2) + 2 # Alice's private secret
b = secrets.randbelow(p - 2) + 2 # Bob's private secret
A = pow(g, a, p) # Alice -> Bob (public)
B = pow(g, b, p) # Bob -> Alice (public)
alice_shared = pow(B, a, p) # Alice computes B^a
bob_shared = pow(A, b, p) # Bob computes A^b
print("Alice and Bob agree:", alice_shared == bob_shared)
print("Shared secret (hex):", hex(alice_shared)[:50], "...")
print("An eavesdropper sees g, p, A, B but must solve discrete log to get the secret.")
Alice and Bob agree: True
Shared secret (hex): 0x85a200f702bffad4fa80003bcb322513f20fe49244a95a75 ...
An eavesdropper sees g, p, A, B but must solve discrete log to get the secret.
ElGamal in Code#
The ElGamal scheme introduced above rests on the same discrete-logarithm hardness as Diffie-Hellman, and the
companion elgamal.cpp implements it end to end over a small prime field for teaching. Key generation picks a
prime p and a primitive root e1, chooses a private key d, and publishes e2 = e1^d mod p; encryption of a
message m with a random r produces the pair (c1, c2) = (e1^r, m * e2^r) mod p; decryption recovers
m = c2 * (c1^d)^(-1) mod p using the modular inverse.
// elgamal.cpp (core) -- fast modular exponentiation and the ElGamal operations
ll mod_exp(ll base, ll e, ll n) { // base^e mod n by square-and-multiply
ll ans = 1;
while (e) { if (e & 1) ans = (ans*base) % n; base = (base*base) % n; e >>= 1; }
return ans;
}
// keygen: e2 = mod_exp(e1, d, p); public (e1,e2,p), private d
// encrypt: c1 = e1^r mod p; c2 = m * e2^r mod p;
// decrypt: m = c2 * modInverse(c1^d, p) mod p; // inverse via extended Euclid
Warning: textbook ElGamal is not secure as-is
Like the AES and RSA teaching programs in this chapter, elgamal.cpp is illustrative. “Textbook” ElGamal is
malleable and is only IND-CPA secure (under the DDH assumption of Section 2.20) when the message is encoded as a
group element and a fresh random r is used for every message; reusing r, or encrypting raw integers, breaks
it. Production use needs proper encoding, an authenticated/hybrid construction, and parameters far larger than
the toy prime used here.
2.12 Elliptic-Curve Cryptography#
Classical RSA and Diffie-Hellman are secure only with large, costly keys. Elliptic curves deliver the same security far more cheaply, which is why they now dominate new systems and why they deserve their own treatment.
RSA and classical Diffie-Hellman are secure only with large keys (2048 bits and up), which cost bandwidth, storage, and computation, an increasing burden on mobile and embedded devices. Elliptic-curve cryptography (ECC) provides the same security with dramatically smaller keys by basing its hard problem on the algebra of points on an elliptic curve rather than on integer factoring or modular exponentiation.
An elliptic curve over a finite field is the set of points satisfying an equation such as y^2 = x^3 + ax + b, together with a special “point at infinity.” One can define an addition operation on these points with the same group structure that makes Diffie-Hellman work. The security rests on the elliptic-curve discrete logarithm problem: given a base point G and a multiple Q = kG (adding G to itself k times), recovering the scalar k is infeasible. Because no sub-exponential algorithm is known for this problem (unlike factoring), ECC keys can be much shorter: a 256-bit elliptic-curve key offers security comparable to a 3072-bit RSA key. This efficiency is why ECC now dominates new deployments.
Practitioners rarely choose curve parameters themselves; they use vetted named curves. Common choices include the NIST curves P-256, P-384, and P-521, and the modern, rigidly designed Curve25519 (used for key exchange as X25519) and its signature counterpart Ed25519, both prized for speed, simplicity, and resistance to implementation pitfalls. The elliptic-curve forms of the standard protocols, ECDH/ECDHE for key exchange and ECDSA/EdDSA for signatures, are the defaults in TLS 1.3, SSH, Signal, and most cryptocurrencies (Bitcoin and Ethereum use the curve secp256k1). When you need asymmetric cryptography today, ECC is usually the right starting point unless interoperability forces RSA.
A little geometry demystifies elliptic-curve “addition.” Over the real numbers, to add two points P and Q on the curve you draw the line through them, find the third point where that line intersects the curve, and reflect it across the x-axis; to “double” a point you use the tangent line instead. Cryptography uses the same rule over a finite field rather than the reals, which scrambles the geometry into something that looks random while preserving the group structure that makes the math work. Scalar multiplication, adding G to itself k times to get kG, is fast (using double-and-add), but inverting it to recover k from kG and G is the hard elliptic-curve discrete-log problem. Because the best known attacks on well-chosen curves are fully exponential, key sizes stay small: 256-bit curves for roughly 128-bit security. Practitioners must still avoid pitfalls, using vetted curves (the rigidity of Curve25519 was designed to remove the suspicion that surrounds some parameter choices), validating that received points actually lie on the curve to prevent invalid-curve attacks, and using constant-time implementations to resist timing side channels.
Elliptic Curves Up Close: Group Law, the ECDLP, and the Curve Zoo#
The high-level claim above, that elliptic-curve cryptography (ECC) matches RSA’s security at far smaller key sizes, becomes concrete once we look at what an elliptic curve actually is and why it yields a hard problem. The following worked example follows the accessible treatment by IoTeX (2018).
An elliptic curve over a finite field is, despite the name, just an algebraic group: a set of points plus one operation, here written as point addition, that is associative, has an identity, and gives every element an inverse. Recall the algebraic hierarchy from Section 2.15: a group has one operation, a ring two, and a field two with division; an elliptic-curve group is built over an underlying field. Take the small prime field \(\mathbb{F}_{11} = \{0, 1, \dots, 10\}\) and the curve
An exhaustive search finds exactly 13 point solutions, namely (0,5), (0,6), (3,3), (3,8), (5,4), (5,7), (6,1), (6,10), (7,0), (9,3), (9,8), (10,3), (10,8), and together with a special point at infinity O they form a group of 14 elements. Points are added by the chord-and-tangent rule: to add P and Q, draw the line through them (the tangent at P if P = Q), find its third intersection with the curve, and reflect over the x-axis to get the result. The identity is O (P + O = P), and the inverse of (x, y) is (x, -y). “Multiplying” a point by an integer k means adding it to itself k times (5P = P + P + P + P + P), an operation called scalar multiplication.
The Elliptic-Curve Discrete Logarithm Problem#
Like every public-key system, ECC rests on a computational problem that is easy one way and infeasible the other. Given a base point P and an integer k, computing Q = kP by scalar multiplication is fast. Going backward, recovering k from P and Q, is the elliptic-curve discrete logarithm problem (ECDLP), and for a curve over a large prime field (on the order of \(2^{256}\) today) no efficient algorithm is known. In the toy \(\mathbb{F}_{11}\) example one could simply tabulate kP for all k and read the answer off, but that table-lookup is hopeless once the field is large, which is exactly what makes the ECDLP a secure foundation in practice. On top of it sit the workhorses of modern ECC: Elliptic-Curve Diffie-Hellman (ECDH) for key exchange and the Elliptic-Curve Digital Signature Algorithm (ECDSA) for signatures, the elliptic-curve analogs of the constructions in Sections 2.11 and 2.13.
The payoff is efficiency. ECC offers RSA-comparable security with much shorter operands (a 256-bit ECC key is broadly comparable to a 3072-bit RSA key), which means smaller keys and signatures and faster, lower-power operations. That profile has made ECC the de-facto choice for resource-constrained and high-volume settings. Standards bodies have codified it: NIST standardized ECC for signatures in FIPS 186 and for key establishment in SP 800-56A, recommending a set of named curves, and the Standards for Efficient Cryptography Group (SECG), founded by Certicom in 1998, published the widely used “SEC 2” curve parameters.
A Field Guide to Modern Curves and Their Uses#
The original NIST and SECG curves have been joined by a newer generation designed for higher performance and stronger resistance to implementation pitfalls, mostly targeting the 128-bit security level. A few that a practitioner will meet in the wild:
Curve25519 (Daniel J. Bernstein, 2005): 128-bit security, designed for ECDH (as X25519), prized for fast, misuse-resistant, constant-time implementations. It underpins the end-to-end encryption in Signal and WhatsApp, and the related Ed25519 is used for signatures across SSH, TLS, and more.
FourQ (Microsoft Research, 2015): 128-bit security, roughly 4 to 5 times faster than NIST P-256.
GLS254 (2013): a binary-field curve at about 127-bit security with very fast implementations.
Koblitz curves such as sect283k1: binary-field curves adopted by the ZigBee Alliance for smart-energy and smart-home devices.
ECC’s small footprint is exactly what makes it the standard for the Internet of Things and for cryptocurrencies. It protects ZigBee Smart Energy, vehicular ad-hoc networks (the V2X setting revisited in Chapters 17 and 20), and near-field communication, and it secures transactions across blockchain platforms (Bitcoin and Ethereum use the Koblitz curve secp256k1). The IoTeX platform, for instance, builds on ECC and on its testnet used the binary Koblitz curve sect283k1, while hiding transaction values not by encryption but with a commitment scheme, a reminder that real systems compose several of this chapter’s primitives rather than relying on any one. The throughline is that the same chord-and-tangent arithmetic over a small toy field scales, unchanged in principle, to the curves guarding billions of devices and dollars.
2.13 Digital Signatures, Certificates, and PKI#
Public-key encryption and key exchange both assume you know whose public key you hold. Signatures and the trust machinery of PKI are how that assumption is justified at internet scale.
A digital signature is the public-key analog of a handwritten signature, but far stronger. To sign, the author hashes the message and transforms the hash with their private key; anyone can verify by checking the signature against the message using the author’s public key. A valid signature proves three things at once: integrity (the message was not altered, or the hash would differ), authentication (only the private-key holder could have produced it), and non-repudiation (the signer cannot credibly deny it, since no one else has the private key). This last property, unique to public-key methods, is why signatures underpin software distribution, legal documents, and blockchain transactions. Standard signature algorithms are RSA-PSS, ECDSA, and EdDSA.
Signatures create a new problem, however: how do you know that a public key really belongs to the party it claims to? If an attacker can substitute their own public key, they can impersonate anyone. The answer is a public-key infrastructure (PKI), a system of trust built on digital certificates. A certificate is a data structure (in the X.509 format) that binds an identity (such as a domain name) to a public key, and is itself signed by a trusted certificate authority (CA). Your browser and operating system ship with a list of trusted root CAs; a website presents a certificate signed by a CA (possibly through a chain of intermediate CAs leading back to a trusted root), and your browser verifies the chain of signatures up to a root it trusts. This delegated trust lets you authenticate a server you have never met.
PKI is powerful but introduces its own risks and machinery: CAs can be compromised or coerced into issuing fraudulent certificates, so mechanisms such as certificate revocation (CRLs and OCSP), Certificate Transparency logs (public, append-only logs of issued certificates, often built on Merkle trees), and short certificate lifetimes exist to detect and contain abuse. Certificate validation failures, expired certificates, name mismatches, untrusted issuers, are among the most common security warnings users see, and training users to click through them undermines the entire system.
It helps to know what a certificate actually contains and how validation really proceeds, since certificate errors are among the most common security decisions an ordinary user faces. An X.509 certificate carries the subject (the identity, such as a domain name, possibly with Subject Alternative Names for multiple hosts), the subject public key, the issuer (the CA that signed it), a validity period (not-before and not-after dates), a serial number, key-usage constraints, and the CA’s digital signature over all of the above. To validate a server’s certificate, a client performs several checks in sequence: it confirms the certificate has not expired, that the requested hostname matches the subject or a SAN, that the certificate has not been revoked (via CRL or OCSP), and, crucially, that the signature chain leads from the server’s certificate, through any intermediate CA certificates, up to a root certificate already in the client’s trust store. Each link is verified by checking that the issuer’s public key validates the next certificate’s signature. If any check fails, the connection should be refused. This chain of trust is powerful but only as strong as its weakest CA, which is why incidents in which a CA was tricked or breached into issuing fraudulent certificates (for example the 2011 DigiNotar compromise, which led to that CA’s removal from trust stores) are treated as serious ecosystem-wide events, and why Certificate Transparency now requires CAs to log every certificate they issue to public, append-only Merkle-tree logs that domain owners can monitor.
Generating a Digital Signature in Code#
A signature binds a message to a private key so anyone with the public key can verify origin and integrity
(non-repudiation). The reference GenerateDigitalSignature.java generates a DSA key pair from a CSPRNG, signs
a file with SHA-1-with-DSA, and writes out the signature and public key.
// GenerateDigitalSignature.java -- DSA key pair, then sign data
KeyPairGenerator keyGen = KeyPairGenerator.getInstance("DSA", "SUN");
keyGen.initialize(1024, SecureRandom.getInstance("SHA1PRNG", "SUN"));
KeyPair pair = keyGen.generateKeyPair();
Signature dsa = Signature.getInstance("SHA1withDSA", "SUN");
dsa.initSign(pair.getPrivate());
dsa.update(data); // feed the bytes to be signed
byte[] signature = dsa.sign(); // verify later with dsa.initVerify(pair.getPublic())
This program is a teaching artifact: 1024-bit DSA and SHA-1 are now considered too weak for new systems (prefer Ed25519 or ECDSA/RSA-PSS with SHA-256, Section 2.12 and 2.13), but the structure, generate keys from a CSPRNG, sign with the private key, verify with the public key, is exactly that of every modern signature scheme.
2.14 Putting It Together: The TLS Handshake#
We have now assembled every primitive separately: key exchange, certificates, signatures, hashing, and authenticated encryption. TLS is where they all come together in the single most important protocol on the internet, so it makes an ideal capstone.
Transport Layer Security (TLS), the protocol behind the padlock in your browser and the “S” in HTTPS, is the most important real-world application of everything in this chapter. It weaves together asymmetric and symmetric cryptography, signatures, certificates, and key exchange to turn an insecure network into a confidential, authenticated channel. The modern version, TLS 1.3 (2018), streamlined and hardened the protocol, removing legacy ciphers and mandating forward secrecy.
At a high level, a TLS 1.3 handshake proceeds as follows. The client opens with a ClientHello that offers its supported cipher suites and includes an ephemeral (EC)DH key share. The server replies with a ServerHello containing its own key share, its certificate, and a signature over the handshake that proves possession of the certificate’s private key. Both sides now combine their ephemeral key shares via (EC)DHE to derive a shared secret, run it through a KDF (HKDF) to produce symmetric session keys, and switch to fast AEAD encryption (AES-GCM or ChaCha20-Poly1305) for all subsequent application data. The ephemeral key exchange provides forward secrecy; the certificate and signature provide server authentication and defeat the man-in-the-middle attack that plain DH would allow.
sequenceDiagram
participant C as Client
participant S as Server
C->>S: ClientHello (cipher suites, ECDHE key share, random)
S->>C: ServerHello (chosen suite, ECDHE key share, random)
S->>C: Certificate (X.509, public key)
S->>C: CertificateVerify (signature over handshake)
S->>C: Finished (MAC over handshake)
Note over C,S: Both derive shared secret via ECDHE, then HKDF -> session keys
C->>S: Finished (MAC over handshake)
Note over C,S: Encrypted application data (AES-GCM / ChaCha20-Poly1305)
Trace each arrow against the primitives in this chapter: key exchange (ECDHE), certificates and signatures (PKI), key derivation (HKDF), and authenticated encryption (AEAD). TLS is a microcosm of applied cryptography, and its history of attacks, BEAST, CRIME, POODLE, Heartbleed, and downgrade attacks, is a catalog of how subtle the engineering is even when the underlying algorithms are sound.
2.15 Advanced and Emerging Cryptography#
The cryptography above secures today’s systems. The frontier, computing on encrypted data and surviving quantum computers, is moving quickly from theory into deployment, and a practitioner should understand where it is heading.
The cryptography above secures today’s internet. A frontier of more powerful constructions is moving from theory into practice, enabling computation on data that stays encrypted, and preparing for a future in which quantum computers threaten the classical assumptions. This section surveys these topics at a level that orients the reader; Chapter 17 develops their security implications further.
Homomorphic encryption (HE) allows computation directly on ciphertext, so that decrypting the result yields the same answer as if the computation had been performed on the plaintext. Partially homomorphic schemes support one operation indefinitely (textbook RSA is multiplicatively homomorphic, and the Paillier cryptosystem is additively homomorphic, meaning that multiplying two ciphertexts modulo n^2 decrypts to the sum of the underlying plaintexts). Fully homomorphic encryption (FHE), first realized by Craig Gentry in 2009, supports arbitrary computation; it remains costly but is advancing rapidly and promises privacy-preserving cloud computing, where a server processes your data without ever seeing it. Functional encryption generalizes public-key encryption so that a specially issued key reveals only a specific function of the plaintext (for example, only whether an encrypted record matches a query) and nothing more, with attribute-based and identity-based encryption as important special cases.
Oblivious computation is a family of techniques for computing on data while hiding access patterns or inputs. Secure multi-party computation (MPC) lets several parties jointly compute a function of their private inputs while learning only the output, the classic illustration being two millionaires who learn who is richer without revealing their wealth. Oblivious transfer (OT) is a primitive in which a receiver obtains one of several items from a sender without the sender learning which, and it is a building block for MPC. Oblivious RAM (ORAM) hides which memory locations a program accesses, defeating attacks that infer secrets from access patterns, and private information retrieval (PIR) lets a user query a database without revealing the query. Zero-knowledge proofs, in which one party proves a statement is true while revealing nothing beyond its truth, are closely related and now central to privacy-preserving blockchains.
Steganography differs in kind from all of the above: rather than making a message unreadable, it hides the very existence of the message, for example by embedding data in the least-significant bits of an image or audio file, where the change is imperceptible. Cryptography and steganography are complementary; encrypting a message before hiding it provides both secrecy and concealment. Steganography is also a defensive concern, since malware uses it for covert command-and-control and data exfiltration, a theme revisited in the forensics and malware chapters. The small code cell demonstrates least-significant-bit image steganography and additive homomorphism.
Going Deeper (graduate/research): the quantum threat and post-quantum cryptography
Large-scale quantum computers would break much of today’s public-key cryptography. Shor’s algorithm solves integer factoring and discrete logarithms in polynomial time, which would defeat RSA, classical Diffie-Hellman, and elliptic-curve cryptography entirely. Grover’s algorithm gives only a quadratic speedup against symmetric primitives, so doubling key and hash sizes (AES-256, SHA-384) restores their security. The defensive response is post-quantum cryptography (PQC): public-key algorithms based on problems believed hard even for quantum computers, principally lattice problems, but also hash-based, code-based, and multivariate constructions. In 2024 NIST standardized the first PQC algorithms, including ML-KEM (the lattice-based key-encapsulation mechanism derived from CRYSTALS-Kyber), ML-DSA (derived from CRYSTALS-Dilithium), and the hash-based signature SLH-DSA (derived from SPHINCS+). A pressing operational concern is the harvest-now, decrypt-later attack, in which adversaries record encrypted traffic today to decrypt once quantum computers mature, which makes migrating long-lived secrets to PQC, often via hybrid classical-plus-PQC schemes, an urgent rather than hypothetical task.
Zero-knowledge proofs deserve a closer look, because they have moved from theoretical curiosity to deployed technology. A zero-knowledge proof lets a prover convince a verifier that a statement is true while revealing nothing beyond the fact of its truth, not the underlying secret. The textbook intuition is the “Ali Baba cave”: a prover repeatedly demonstrates they can open a secret door without ever showing the verifier the password, by emerging from whichever side the verifier randomly demands. Formally, a zero-knowledge proof must satisfy completeness (a true statement is accepted), soundness (a false statement is rejected except with negligible probability), and the zero-knowledge property (the verifier learns nothing they could not have produced alone). Modern non-interactive variants, notably zk-SNARKs and zk-STARKs, compress such proofs to small sizes that anyone can verify, and they now power privacy-preserving cryptocurrencies (proving a transaction is valid without revealing its amounts or parties) and scalability systems that prove the correctness of large computations cheaply. Zero-knowledge proofs combine naturally with the secure-computation primitives above, and together they point toward a future in which one can prove properties of data, and compute on it, without ever exposing it, which is why this area is among the most active in both research and industry.
Computing Paradigms: Mainframes, Classical, DNA, and Quantum#
Because the security of modern ciphers rests on what is computationally feasible, the nature of the computer doing the work matters, and several computing paradigms, past and emerging, frame both cryptography and cryptanalysis. Mainframes, the large, centralized computers that dominated mid-twentieth-century computing and still run critical banking and government workloads, established the multi-user, high-reliability batch processing on which early cryptographic and security models were built; they are classical computers in the sense below, distinguished by scale and reliability rather than by a different model of computation. Classical computers, from mainframes to laptops to smartphones, all share the same foundation: they manipulate bits that are definitely 0 or 1 using Boolean logic, and (per the Church-Turing model) they are equivalent in what they can compute, differing only in speed and memory. The security of AES, RSA, and elliptic-curve cryptography is calibrated against the best algorithms running on classical computers, which is why key sizes are chosen so that brute force would take longer than the age of the universe on any foreseeable classical hardware.
Two non-classical paradigms change this calculus. DNA computing uses strands of DNA and biochemical reactions to perform computation, exploiting the massive parallelism of manipulating trillions of molecules at once; Leonard Adleman (the A in RSA) demonstrated in 1994 that DNA could solve a small instance of a hard combinatorial problem. DNA computing is of research interest for certain massively parallel search problems and for ultra-dense data storage, but it is slow, error-prone, and impractical for general cryptanalysis, so it does not currently threaten modern ciphers. Quantum computers, by contrast, use qubits that can exist in superpositions of 0 and 1 and become entangled, enabling certain algorithms to explore many possibilities at once. As Section 2.15 details, this is not a generic speedup but a targeted one: Shor’s algorithm would efficiently solve the factoring and discrete-logarithm problems that secure RSA and elliptic-curve cryptography, breaking them outright, while Grover’s algorithm offers only a quadratic speedup against symmetric ciphers and hashes, which larger keys offset. This asymmetry, devastating to public-key cryptography but survivable for symmetric cryptography with bigger keys, is precisely why the migration to post-quantum algorithms targets key exchange and signatures first. The broad lesson is that cryptographic strength is always relative to the adversary’s computational model, and a paradigm shift in computing, as quantum computing may bring, forces a corresponding shift in cryptography.
Searchable, Deniable, and Functional Encryption#
The advanced primitives above mostly preserve confidentiality outright; a further family relaxes or reshapes confidentiality to enable specific functionality, and each is an active research area. Searchable encryption (SE) lets a server search over ciphertext without decrypting it: a client stores encrypted documents and later submits an encrypted query (a “trapdoor”), and the server returns the matching ciphertexts while learning as little as possible about the data or the query. Symmetric searchable encryption (SSE) is efficient and practical, public-key variants (PEKS, public-key encryption with keyword search) allow others to write searchable encrypted data, and the central research tension is the trade-off between efficiency and leakage: most practical schemes reveal some access and search patterns, which leakage-abuse attacks can exploit, so the field studies exactly how much leakage is safe. Searchable encryption underpins encrypted databases and privacy-preserving cloud storage.
Deniable encryption addresses coercion: a deniable scheme lets a single ciphertext decrypt to two different plausible plaintexts under two different keys, so that a user compelled to reveal a key can hand over a key that yields an innocuous message while the real message stays hidden under another key. The ciphertext alone gives an adversary no way to prove that a second, “real” plaintext exists, which provides protection against rubber-hose (coercive) attacks and is relevant to whistleblowers and censorship resistance. Deniability can be sender-, receiver-, or bi-deniable, and it connects to plausible-deniability features in some disk-encryption and messaging systems.
Functional encryption (FE), introduced in the earlier advanced section, generalizes public-key encryption so that a decryptor holding a function-specific key learns only f(plaintext), not the plaintext itself; attribute-based and identity-based encryption are important special cases, and function secret sharing and distributed point functions are closely related tools (active topics in current research, for example in private information retrieval and anonymous communication). Together, searchable, deniable, and functional encryption illustrate a broad theme of modern cryptography: rather than treating encrypted data as an opaque blob, these schemes allow precisely controlled computation, search, or disclosure over ciphertext, expanding what is possible while carefully bounding what is leaked.
The Algebra Beneath Cryptography: Finite Fields, Abelian and Non-Abelian Groups#
Almost every cryptosystem in this chapter is built on abstract algebra, and a little of its vocabulary clarifies why the schemes work and where new ones come from. A group is a set with an operation that is associative, has an identity element, and gives every element an inverse. A group is abelian (commutative) if the operation order does not matter (a * b = b * a) and non-abelian otherwise. Most classical public-key cryptography lives in abelian groups: RSA works in the multiplicative group of integers modulo n, and Diffie-Hellman and elliptic-curve cryptography work in cyclic abelian groups where the discrete-logarithm problem is hard. A finite field (Galois field, written GF(p) or GF(2^n)) is a finite set supporting addition, subtraction, multiplication, and division; AES, for instance, performs its MixColumns and S-box arithmetic in GF(2^8), and finite fields underlie error-correcting codes, secret sharing, and elliptic curves. Discrete mathematics, modular arithmetic, number theory, combinatorics, and group theory, is therefore the true foundation of cryptography, which is why courses pair the two.
A frontier of research explores non-abelian structures for cryptography, where the operation does not commute (as in certain matrix groups, braid groups, or group-ring constructions). The motivation is partly the search for problems that resist quantum attacks: because Shor’s algorithm efficiently solves the abelian hidden-subgroup problem (which is why it breaks RSA and elliptic-curve cryptography), schemes based on suitably hard non-abelian or non-commutative problems are studied as potential post-quantum candidates, alongside the lattice-, code-, and hash-based families that NIST has standardized. Non-abelian proposals remain largely research-stage and many early ones were broken, but they illustrate how the algebraic structure a cryptosystem rests on directly determines both its security and its vulnerability to particular attacks. For the reader, the practical takeaway is that understanding the underlying algebra, which group, which field, which hard problem, is what lets one reason about a cryptosystem rather than merely use it.
Going Deeper (graduate/research): why “abelian” matters for quantum security
Shor’s algorithm is, at its core, an efficient quantum solution to the hidden-subgroup problem (HSP) over finite abelian groups. Integer factoring and discrete logarithms reduce to abelian HSP instances, which is exactly why RSA, Diffie-Hellman, and elliptic-curve cryptography fall to a large quantum computer. For non-abelian groups, no general efficient quantum algorithm for the HSP is known; the symmetric and dihedral hidden-subgroup problems, for instance, remain hard, and the dihedral HSP connects to the lattice problems behind post-quantum schemes such as ML-KEM. This is the deep reason the post-quantum migration moves toward lattice-, code-, hash-, and multivariate-based hardness, and why non-commutative cryptography is studied: the structure of the group determines whether a quantum Fourier transform can break it. This links the finite-field and group-theory foundations of this section directly to the quantum threat and post-quantum cryptography discussed earlier in the chapter.
Lattice-Based Cryptography: The Hard Problems Behind Post-Quantum Schemes#
Most of the post-quantum standards rest on the difficulty of problems on lattices. A lattice is a regular, infinitely repeating grid of points in n-dimensional space, generated by adding integer multiples of a set of basis vectors. The same lattice has many valid bases: a good basis is short and nearly orthogonal, so it is easy to find the nearest grid point, while a bad basis is long and skewed, so the structure is hard to navigate. Lattice cryptosystems exploit this gap by publishing a bad basis as the public key while keeping a good basis as the private key.
Their security reduces to problems believed hard for both classical and quantum computers, whose difficulty grows quickly with the lattice dimension:
Shortest Vector Problem (SVP): given a basis, find the shortest non-zero vector in the lattice. This is the foundational hard problem.
Gap Shortest Vector Problem (GapSVP): the decision form, deciding whether the shortest vector is shorter than, or far longer than, a given bound.
Closest Vector Problem (CVP): given an arbitrary target point (not necessarily on the lattice), find the nearest lattice point. CVP underlies early schemes such as GGH (Goldreich-Goldwasser-Halevi).
Short Integer Solution (SIS): find a short, non-zero integer combination of given vectors that sums to zero under a modular function; SIS underpins many lattice signatures.
Learning With Errors (LWE): recover a secret vector from many linear equations perturbed by small random errors (noise). The noise is what makes recovery hard, and LWE provably reduces from worst-case lattice problems. Ring-LWE is a more efficient variant over polynomial rings that shrinks key sizes by giving the lattice algebraic structure.
These problems anchor the NIST post-quantum standards: ML-KEM (FIPS 203, key encapsulation, from CRYSTALS-Kyber) and ML-DSA (FIPS 204, signatures, from CRYSTALS-Dilithium) build on module-LWE and module-SIS, and NTRU is an efficient ring-lattice scheme based directly on finding short vectors. Their cost is larger keys and ciphertexts than RSA or ECC, which is the main practical hurdle in the post-quantum migration. The toy example below shows the core LWE idea: encryption hides a bit under noise that only the secret can remove.
The Mathematics of Lattices#
A lattice is generated by a set of linearly independent basis vectors, and the same lattice can be described by many different bases. Two full-rank bases generate the identical lattice exactly when one is obtained from the other by multiplication with a unimodular matrix (an integer matrix with determinant plus or minus one). A basis defines a fundamental parallelepiped whose n-dimensional volume equals the absolute value of the determinant of the basis matrix; this volume is invariant across equivalent bases even though their shapes differ, and it measures how sparse the lattice is. Gram-Schmidt orthogonalization turns a basis into an orthogonal set and yields a useful bound: the length of the shortest nonzero vector, written lambda_1, is at least the smallest Gram-Schmidt vector length, while Minkowski’s theorem gives a matching upper bound in terms of the lattice volume. The dual lattice, the set of vectors whose inner product with every lattice vector is an integer, is a further tool used throughout lattice cryptanalysis and in the worst-case-to-average-case reductions that give lattice cryptography its unusual security guarantees. Distances are measured with vector norms, most often the Euclidean (L2) norm, so the hard problems above are really about finding short or close vectors under that norm.
Beyond the schemes already named, the lattice family includes NTRU (an efficient ring-lattice encryption scheme dating to 1996), BLISS (a lattice-based signature scheme), and NewHope (a Ring-LWE key exchange evaluated during the NIST process). The hardness of Ring-LWE also underpins the most practical fully homomorphic encryption schemes. Homomorphic encryption lets computation run directly on ciphertext: partially homomorphic schemes support one operation without limit (RSA and ElGamal are multiplicatively homomorphic, Paillier is additively homomorphic, and Goldwasser-Micali is homomorphic over exclusive-or), whereas fully homomorphic encryption (FHE), built on lattice problems, supports both addition and multiplication and can therefore evaluate arbitrary circuits on encrypted data, the subject of the privacy-preserving computation in Chapter 17.
Three Families by Underlying Structure: Abelian, Non-Abelian, and Lattice#
It is worth stating plainly how these hard problems map to families of schemes, because the underlying structure determines both efficiency and quantum resistance.
Abelian-group-based schemes are today’s deployed public-key cryptography. RSA lives in the multiplicative group of integers modulo n (hardness: integer factoring); Diffie-Hellman and ElGamal live in a cyclic abelian group (hardness: the discrete-logarithm problem); and elliptic-curve cryptography uses the abelian group of points on a curve (hardness: the elliptic-curve discrete-logarithm problem). All of these fall to Shor’s algorithm because they reduce to the abelian hidden-subgroup problem.
Non-abelian-group-based schemes are a research direction that uses groups whose operation does not commute, in the hope that the relevant problems escape Shor’s reach. The best-known proposals are braid-group key exchanges such as Anshel-Anshel-Goldfeld and Ko-Lee, whose security rests on variants of the conjugacy-search problem. These remain experimental, and many early constructions were cryptanalyzed, so none is standardized.
Lattice-based schemes are the leading post-quantum family and rest on the lattice problems above. The Shortest Vector Problem (SVP), finding the shortest non-zero vector, captures the core hardness, while the Closest Vector Problem (CVP), finding the lattice point nearest an arbitrary target, is what an attacker must solve to decrypt a GGH-style ciphertext. Encryption adds a small error to a lattice point, and legitimate decryption uses the good (private) basis to solve a bounded-distance instance of CVP that an attacker holding only the bad (public) basis cannot. NTRU, and the standardized ML-KEM and ML-DSA, build on these problems and their LWE and SIS variants.
The throughline is that the algebraic structure a scheme rests on, an abelian group, a non-abelian group, or a lattice, simultaneously determines its efficiency and its resistance to quantum attack, which is exactly why the migration in Section 2.21 moves away from abelian-group hardness.
# Chapter 2 -- Toy Learning With Errors (LWE): encrypt and decrypt one bit
# Illustration only; real schemes (ML-KEM) use far larger, carefully chosen parameters.
import numpy as np
rng = np.random.default_rng(0)
n, m, q = 8, 40, 257 # secret dimension, samples, modulus
s = rng.integers(0, q, size=n) # private key (the secret vector)
A = rng.integers(0, q, size=(m, n)) # public matrix
e = rng.integers(-1, 2, size=m) # small noise in {-1, 0, 1}
b = (A @ s + e) % q # public key is (A, b)
def encrypt(bit):
idx = rng.integers(0, 2, size=m) # random subset of the public samples
u = (idx @ A) % q
v = (idx @ b + bit * (q // 2)) % q # hide the bit near 0 or q/2
return u, v
def decrypt(u, v):
d = (v - u @ s) % q # remove the secret; noise remains
return 1 if min(d, q - d) > q // 4 else 0 # close to q/2 -> 1, close to 0 -> 0
ok = all(decrypt(*encrypt(bit)) == bit for bit in [0, 1, 0, 1, 1, 0, 1, 0, 0, 1])
print("LWE toy round-trip correct:", ok)
LWE toy round-trip correct: True
# Chapter 2 -- LSB image steganography and additive homomorphism (self-contained)
import numpy as np
# --- Least-significant-bit steganography ---
def hide(cover, message):
bits = "".join(f"{b:08b}" for b in message.encode()) + "00000000" # null terminator
flat = cover.flatten().copy()
for i, bit in enumerate(bits):
flat[i] = (flat[i] & 0xFE) | int(bit) # overwrite the least significant bit
return flat.reshape(cover.shape)
def reveal(stego):
flat = stego.flatten()
bits, out = "", []
for v in flat:
bits += str(v & 1)
if len(bits) == 8:
if bits == "00000000": break
out.append(int(bits, 2)); bits = ""
return bytes(out).decode(errors="ignore")
cover = np.random.randint(0, 256, (64, 64), dtype=np.uint8)
stego = hide(cover, "meet at noon")
print("Hidden message recovered:", repr(reveal(stego)))
print("Max pixel change:", int(np.abs(cover.astype(int) - stego.astype(int)).max()), "(imperceptible)\\n")
# --- Additive homomorphism (toy Paillier-style intuition with simple modular adds) ---
# Demonstrate that some encryptions let you add underneath encryption.
# Here: textbook RSA is *multiplicatively* homomorphic: E(a)*E(b) = E(a*b)
def egcd(a,b):
return (a,1,0) if b==0 else (lambda g,x,y:(g,y,x-(a//b)*y))(*egcd(b,a%b))
n, e = 3233, 17 # toy RSA modulus (61*53)
Ea, Eb = pow(7,e,n), pow(3,e,n)
print("E(7)*E(3) mod n decrypts to 7*3 = 21 ->", (Ea*Eb) % n, "is E(21); homomorphic property holds")
Hidden message recovered: 'meet at noon'
Max pixel change: 1 (imperceptible)\n
E(7)*E(3) mod n decrypts to 7*3 = 21 -> 1188 is E(21); homomorphic property holds
2.16 Key Management#
If the previous sections taught how algorithms work, this one addresses the problem that breaks more real systems than any algorithmic weakness: managing the keys those algorithms depend on. A cipher is only as strong as the secrecy and integrity of its keys, and the unglamorous discipline of key management spans the entire lifecycle of a key, generation, distribution, storage, use, rotation, revocation, and destruction.
Generation must use a CSPRNG with adequate entropy, as Section 2.4 stressed; a key guessable because of weak randomness is no key at all. Distribution is the classic problem that public-key cryptography and key-exchange protocols solve, but symmetric keys shared out of band must travel over an already-secure channel. Storage is where keys most often leak: hard-coding keys in source code, committing them to version control, or leaving them in configuration files and environment variables has exposed countless organizations. The defenses are dedicated key vaults and, for the highest assurance, hardware security modules (HSMs), tamper-resistant devices that generate and use keys internally so the private key never leaves the hardware in plaintext. On endpoints, a Trusted Platform Module (TPM) plays an analogous role, anchoring disk-encryption and platform-integrity keys in hardware.
Use should honor key separation (a key serves one purpose, for example never reusing an encryption key as a signing key) and cryptoperiods (limits on how much data or time a key covers). Rotation periodically replaces keys to limit the damage of an undetected compromise and to bound the data encrypted under any single key. Revocation invalidates keys and certificates known or suspected to be compromised, the PKI machinery of Section 2.13. Finally, destruction ensures retired keys cannot be recovered, which is also the basis of crypto-shredding: deliberately destroying the key to render encrypted data permanently unreadable, a powerful tool for data disposal and the right to erasure. A related governance question is key escrow, storing a copy of keys with a trusted third party so data can be recovered (or lawfully accessed); escrow improves recoverability but creates a high-value target and civil-liberties concerns, a tension explored further in the privacy and law chapter. Mature organizations formalize all of this in a key-management policy and increasingly automate it through key-management services, because manual key handling does not scale and does not survive employee turnover.
For the highest-value keys, organizations apply two further controls worth knowing by name. Split knowledge divides a key (or the secret that protects it) so that no single person holds the whole thing; reconstructing it requires several authorized people to combine their parts, which prevents any lone insider from misusing it. The formal mechanism is secret sharing, most famously Shamir’s scheme, which splits a secret into n shares such that any threshold t of them reconstructs it but any fewer reveal nothing, often described as M-of-N control. Dual control similarly requires two authorized operators to act together for sensitive key operations, the cryptographic analog of the two-person rule for launching weapons. These controls trade some convenience for strong protection against insider compromise and accidental loss, and they appear directly in standards governing payment systems and certificate authorities, connecting this section to the governance and compliance material later in the book.
Key Management Services and Key Escrow#
At scale, key management is delegated to a dedicated Key Management Service (KMS), a centralized, access-controlled system (often HSM-backed) that generates, stores, rotates, and audits keys so that applications never handle raw key material directly. Cloud KMS offerings (AWS KMS, Azure Key Vault, Google Cloud KMS) are the common examples. The pattern they enable is envelope encryption: data is encrypted locally with a fast, per-object data key, and that data key is itself encrypted (“wrapped”) by a master key-encryption key that never leaves the KMS. Only the wrapped data key is stored alongside the ciphertext; to decrypt, the application asks the KMS to unwrap the data key, which lets the KMS enforce fine-grained access policies and log every key use (the auditability of Section 2.20) without ever exposing the master key. This is how the at-rest and server-side encryption of Chapter 17 are managed in practice, and it embodies least privilege (Chapter 1): an application can request decryption only of the keys its policy allows.
Key escrow is a distinct and more controversial idea: deliberately depositing a copy of a key (or a means to recover it) with a trusted third party so that data can be recovered if the key is lost or accessed under defined conditions. Legitimate uses include enterprise key-recovery (so an employee’s departure or a forgotten password does not permanently lock business data) and regulatory archival. The controversy is the government-access form of escrow, in which authorities hold a recovery key for lawful interception, the center of the 1990s “Crypto Wars” and the failed Clipper chip, and of recurring “exceptional access” debates today. The security objection is fundamental: any escrowed key is a high-value single point of failure and a built-in backdoor that can be stolen, misused, or compelled, weakening the system for everyone. The engineering consensus, reflected in the rest of this chapter, is that escrow trades away the very properties (confidentiality, forward secrecy) that strong cryptography is meant to provide, so where key recovery is genuinely required it should use carefully controlled, audited, organization-internal mechanisms rather than a universal third-party backdoor.
2.17 A Taxonomy of Cryptographic Attacks#
Having seen how cryptography is built, we close the technical material by cataloging how it is broken, because choosing and configuring cryptography well means anticipating the adversary. CISSP’s Domain 3 tests exactly this vocabulary, and the categories below recur throughout the book.
Attacks divide first by what the adversary can access. In a ciphertext-only attack the adversary sees only ciphertext; in a known-plaintext attack they have some plaintext-ciphertext pairs; in a chosen-plaintext attack (CPA) they can encrypt messages of their choosing; and in a chosen-ciphertext attack (CCA) they can submit ciphertexts for decryption and observe the result. Modern schemes are designed to resist the strongest of these, which is why IND-CPA and IND-CCA are the benchmark security goals introduced earlier.
A second family targets the mathematics or the key. Brute-force attacks try every key and are defeated only by sufficient key length. Birthday attacks exploit the square-root collision bound to forge hashes or MACs with shorter digests. Mathematical attacks attempt to solve the underlying hard problem more cleverly (improved factoring or discrete-log algorithms), and quantum algorithms, discussed in Section 2.15, are the extreme case. Frequency analysis, from Section 2.2, is the classical ancestor of all statistical attacks.
The most important family in practice attacks the implementation rather than the algorithm. Side-channel attacks extract secrets from physical leakage, timing, power consumption, electromagnetic emissions, or even sound, and timing attacks in particular have repeatedly recovered keys from naive code, which is why constant-time implementations and constant-time comparisons matter. Fault-injection attacks deliberately induce hardware errors to expose keys. Padding-oracle attacks (Section 2.8) turn a decryptor’s error behavior into a plaintext leak. Replay attacks resend captured valid messages, defeated by nonces and timestamps. Downgrade attacks trick parties into negotiating weaker, breakable parameters, the reason protocols must refuse obsolete ciphers. And the man-in-the-middle attack, which plain Diffie-Hellman invites, is defeated only by authentication. The unifying insight, repeated deliberately throughout this chapter, is that strong algorithms are necessary but never sufficient: security is a property of the whole system, including its randomness, its key management, its protocol design, and the code that implements it.
2.18 Applied Cryptographic Systems#
The TLS handshake showed primitives combining into one protocol. To make the chapter’s relevance concrete, this section briefly surveys the other systems you use every day that are, underneath, the same building blocks rearranged. Each is developed further in later chapters; the goal here is to see the cryptography at work.
Full-disk and file encryption protect data at rest. Tools such as BitLocker, FileVault, and LUKS encrypt entire volumes with a symmetric cipher (AES in a length-preserving mode such as XTS designed for storage), while the disk key is itself protected by a key derived from the user’s password and, ideally, sealed in a TPM so that the disk cannot be decrypted on different hardware. This is why a stolen but powered-off encrypted laptop usually protects its data, and why the possession property of the Parkerian hexad, lost when the hardware is taken, still does not imply loss of confidentiality.
Secure messaging brought strong end-to-end encryption (E2EE) to billions of people. The Signal protocol, used by Signal, WhatsApp, and others, combines an initial ECDH key agreement (X3DH) with the double ratchet, which derives a fresh key for every message so that compromising one key exposes neither past nor future messages, properties called forward secrecy and post-compromise security. E2EE means the service provider itself cannot read message contents, which is also why it is a recurring point of tension with law enforcement, revisited in the privacy and law chapter.
Virtual private networks (VPNs) create an encrypted tunnel across an untrusted network. IPsec and the modern, compact WireGuard protocol authenticate the endpoints and then carry traffic under authenticated encryption, applying the same key-exchange-then-symmetric pattern as TLS at the network layer. Code signing uses digital signatures so that operating systems and app stores install only software whose signature verifies against a trusted developer key, the defense whose subversion made the SolarWinds supply-chain attack so damaging. Cryptocurrencies combine hash-linked Merkle-tree ledgers with elliptic-curve signatures: ownership of funds is simply possession of a private key, which makes key management (Section 2.16) a matter of real money and explains why lost or stolen keys translate directly into lost or stolen value. Across all of these, notice the recurring grammar of applied cryptography: agree on a key, encrypt with AEAD, authenticate with signatures or MACs, and manage keys carefully. Once you see that grammar, unfamiliar secure systems become readable.
2.19 Practical Guidance: Choosing and Using Cryptography#
After surveying primitives, attacks, key management, and applications, a practitioner needs a compact set of rules for making real decisions, which this section provides as the chapter’s actionable conclusion.
The first and most important rule is do not roll your own cryptography. Implementing ciphers, protocols, or even padding from scratch is how subtle, fatal bugs enter systems; use well-maintained, widely reviewed libraries (such as libsodium, the cloud providers’ key-management services, or a language’s vetted standard library) and use their high-level “easy” interfaces, which make the safe choice the default. The second rule is prefer authenticated encryption (AEAD) for confidentiality so that integrity comes for free; never deploy a mode that provides confidentiality alone. The third is to choose modern algorithms with adequate parameters, summarized below as sensible defaults for new systems as of the mid-2020s.
Need |
Recommended default |
Avoid |
|---|---|---|
Symmetric encryption |
AES-256-GCM or ChaCha20-Poly1305 (AEAD) |
ECB; unauthenticated CBC; DES/3DES; RC4 |
Hashing |
SHA-256, SHA-3, or BLAKE2 |
MD5, SHA-1 |
Password storage |
Argon2id (or scrypt/bcrypt) with unique salt |
plain or fast-hashed passwords |
Key exchange |
X25519 / ECDHE (ephemeral, forward secret) |
static DH; non-ephemeral exchange |
Public-key encryption/signatures |
RSA-3072+ with OAEP/PSS, or Ed25519/ECDSA |
textbook RSA; short keys |
Random values |
OS CSPRNG ( |
|
Long-term/quantum exposure |
hybrid classical + ML-KEM/ML-DSA |
classical-only for decades-long secrets |
Two further disciplines distinguish mature programs. Crypto-agility is designing systems so algorithms can be replaced without re-architecting, which the looming post-quantum migration makes urgent; hard-coding a single cipher or key size is now considered a design flaw. Compliance and validation matter in regulated environments: standards such as FIPS 140-3 certify cryptographic modules, and frameworks discussed in later chapters often mandate specific algorithms and key lengths. Finally, remember that cryptography is a means, not an end. It enforces confidentiality, integrity, and authentication, but it cannot secure a compromised endpoint, fix a flawed protocol, or compensate for poor key management. Used correctly, within a system designed with the principles of Chapter 1, it is the strongest tool we have; used carelessly, it provides a false sense of security that can be worse than none at all.
2.19a Protecting Data in All Three States#
A practical way to organize everything this chapter provides is by the state the data is in, because each state needs a different protection and together they are a checklist for any system.
Data at rest is stored data (files, databases, backups, disks). It is protected by encryption at rest: full-disk encryption, database/field encryption, and encrypted object storage (server-side encryption, Chapter 17), so a stolen disk or backup yields only ciphertext.
Data in transit is data moving across a network. It is protected by encryption in transit: TLS (Section 2.14), IPsec, and SSH, so an on-path attacker (Chapter 3) captures only ciphertext. This is the defense against the plaintext-password sniffing demonstrated in Chapter 3.
Data in use (in execution) is data being processed in memory by an application, historically the hardest to protect because it must be decrypted to compute on. Two modern approaches address it. Trusted execution environments (TEEs) and confidential computing, such as Intel SGX enclaves and AMD SEV encrypted VMs, keep data encrypted in memory and decrypt it only inside a hardware-isolated region (this connects to the CPU rings and TEE discussion of Chapter 1). Homomorphic encryption (Section 2.15 and Chapter 17) goes further, computing directly on ciphertext so the data is never decrypted at all, the property the author’s SigML/SplitML work exploits.
A complete design covers all three states: a credential encrypted at rest and in transit but exposed in plaintext while processed (data in use) is still at risk, which is exactly why confidential computing and homomorphic encryption are active frontiers. This also refines the client-side versus server-side encryption choice of Chapter 17: client-side encryption protects data in transit and at the server, leaving only data-in-use as the residual risk.
2.19b Tamper-Evident and Tamper-Proof Mechanisms#
Integrity (this chapter) and physical security (Chapter 20) meet in two related but distinct goals that systems often confuse. A tamper-evident mechanism does not prevent tampering but guarantees that any tampering can be detected after the fact: examples include cryptographic hashes and MACs (Section 2.8), digital signatures, append-only and hash-chained audit logs, blockchain ledgers, and the physical security seals on packaging and voting machines. A tamper-proof (more accurately tamper-resistant) mechanism aims to prevent or actively resist tampering, and because perfect prevention is unattainable, strong designs add tamper-responsive behavior that destroys secrets when intrusion is detected. Examples are hardware security modules (HSMs), Trusted Platform Modules (TPMs), smart-card secure elements, and the secure enclaves above, which zeroize keys if the chip is probed or decapped.
The two goals are complementary, and good systems combine them: a tamper-resistant HSM protects keys while a tamper-evident audit log records every use, so that what cannot be prevented can at least be detected and attributed (the non-repudiation and auditability properties of Section 2.20). The design rule is to assume a determined adversary will eventually defeat any single barrier, so confidentiality should rest on tamper- resistant key storage and integrity on tamper-evident records, never on the hope that a barrier is truly “tamper-proof.”
2.20 Formal Security Analysis and Provable Security#
Throughout this chapter we have asserted that schemes are “secure,” and in Section 2.3 we made one such claim precise with the IND-CPA game. This final section steps back to ask the general question that organizes modern cryptography: what does it mean to prove a system secure, and how is such a proof structured? Provable (reductionist) security answers a security question not by failing to find an attack but by reducing breaking the scheme to solving a problem believed to be hard, so that any efficient attack would also solve that hard problem. Reading and writing such analyses is a core skill for graduate study and for the research threads in Chapter 17, and it rests on four ingredients that every rigorous definition makes explicit.
The Anatomy of a Security Definition#
Before any theorem, a security analysis must pin down four things, and naming them is also the discipline of threat modeling and security-requirements analysis.
The asset being protected. What exactly must be kept safe: the plaintext’s confidentiality, a message’s integrity, a signer’s identity, a user’s anonymity?
The adversary model. What can the attacker do? Is it passive (eavesdropping only) or active (injecting, modifying, replaying)? Is it bounded to probabilistic polynomial time (the computational model) or unbounded (the information-theoretic model of Section 2.3)? What oracle access does it get, an encryption oracle (CPA), a decryption oracle (CCA1/CCA2), a signing oracle (CMA)? Defining the adversary’s capabilities precisely is what makes a claim falsifiable.
The security goal. Stated as a game the adversary tries to win and an advantage it must keep negligible: indistinguishability, unforgeability, and so on.
The assumptions. The hardness assumptions (below), trust assumptions (who is honest), and setup assumptions (a public-key infrastructure, a common reference string, a random oracle).
A practical way to build the adversary model is to interrogate the design with concrete what-if questions, each of which corresponds to a capability the proof must cover:
What if… |
Capability it models |
Defense it forces |
|---|---|---|
the server is malicious? |
a dishonest party, not just an eavesdropper |
end-to-end guarantees, verifiable computation, malicious-secure MPC |
two users collude? |
corrupted-coalition adversary |
collusion-resistant keying, threshold trust |
keys are leaked? |
key-compromise adversary |
forward secrecy, key rotation, compartmentalization |
messages are replayed? |
replay adversary |
nonces, sequence numbers, timestamps |
timestamps are manipulated? |
adversary controls time/ordering |
authenticated, monotonic counters; trusted time |
randomness is predictable? |
weak-randomness adversary |
CSPRNGs, nonce-misuse-resistant modes (Section 2.8) |
These questions are not rhetorical; each one that the model fails to answer is a gap a real attacker can walk through, which is why the history in Section 2.8 is a catalog of overlooked adversary capabilities.
Hardness Assumptions and the Random Oracle Model#
Computational security is always conditional: a scheme is secure assuming some mathematical problem is hard. The two assumptions behind most discrete-log cryptography, including Diffie-Hellman (Section 2.11) and ElGamal, are:
The Computational Diffie-Hellman (CDH) assumption: given g, g^a, g^b in a suitable group, it is infeasible to compute g^{ab}.
The Decisional Diffie-Hellman (DDH) assumption: it is infeasible even to distinguish g^{ab} from a random group element given g, g^a, g^b. DDH is strictly stronger than CDH (distinguishing is easier than computing), and many indistinguishability proofs need it.
The payoff is concrete: ElGamal encryption is IND-CPA secure if and only if DDH holds in the underlying group, a clean example of a semantic-security theorem that ties a scheme’s confidentiality directly to a studied mathematical problem (recall from Section 2.3 that IND-CPA and semantic security are equivalent). Where a clean assumption is not enough, proofs sometimes invoke the Random Oracle Model (ROM) of Bellare and Rogaway (1993), an idealization that treats a hash function as a truly random function the adversary may only query. ROM proofs (used for RSA-OAEP, RSA-PSS, Fiat-Shamir signatures) are efficient and widely trusted in practice, but they are a heuristic: a proof in the ROM is not the same as a proof in the standard model (no idealized oracle), and contrived schemes exist that are ROM-secure yet insecure under every real hash, so practitioners prefer standard-model proofs when they are available.
The Zoo of Security Notions#
Different primitives need different goals, and the literature has a compact vocabulary for them, several of which this chapter has already used. Confidentiality notions form the IND ladder of Section 2.3; signatures and MACs have their own unforgeability notion.
Notion |
Primitive |
Adversary wins by… |
|---|---|---|
IND-CPA |
encryption |
distinguishing encryptions of two chosen messages, with an encryption oracle |
IND-CCA1 / IND-CCA2 |
encryption |
the same, with a decryption oracle before (CCA1) or also after (CCA2) the challenge |
IND-CPA^D |
approximate/leaky-decryption HE |
distinguishing when honest decryptions are shared (Section 2.8) |
NM-CPA / NM-CCA2 |
encryption |
producing a ciphertext whose plaintext is related to the target (non-malleability) |
EUF-CMA |
signatures / MACs |
forging a valid signature on a new message, given a signing oracle |
SUF-CMA |
signatures / MACs |
forging any new (message, signature) pair, even a new signature on a signed message |
EUF-CMA (existential unforgeability under adaptive chosen-message attack), the accepted standard for signatures, was first formalized by Goldwasser, Micali, and Rivest (1988) along with the GMR scheme: the adversary receives the public key, may request signatures on messages of its choice, and must output a valid signature on a message it never queried; the scheme is secure if every efficient adversary’s success probability is negligible. The strict variant SUF-CMA additionally forbids forging a new signature even on an already-signed message, a property authenticated-encryption and some protocol proofs rely on.
Simulation-Based Security and Universal Composability#
Game-based definitions like IND-CPA are perfect for single primitives, but complex protocols (secure multi-party computation, oblivious transfer, the privacy-preserving ML of Chapter 17) need a different lens: simulation-based security. The idea is to compare the real protocol against an ideal one in which a trusted party simply computes the function and hands back the answer. A protocol is secure if whatever an adversary learns or achieves in the real execution, it could also have achieved in the ideal world, formalized by exhibiting a simulator that, with only the ideal-world information, reproduces the adversary’s real-world view. If real and ideal are indistinguishable, the protocol “leaks nothing beyond the output,” which is exactly the guarantee one wants for, say, encrypted inference that should reveal only the prediction.
The strongest form of this idea is Universal Composability (UC), introduced by Canetti (2001). Ordinary simulation security can break when many protocol instances run concurrently and interact; UC closes that gap. Its central composition theorem guarantees that a protocol proven UC-secure in isolation remains secure when composed arbitrarily with other protocols and run in many concurrent instances under adversarial scheduling. This is invaluable for real systems, where no protocol runs alone, though UC security is demanding and often requires setup assumptions such as a common reference string. UC is the gold standard for protocol design and the framework in which much modern MPC, commitment, and authentication work is proved.
Symbolic Models: Dolev-Yao and Automated Verification#
The proofs above live in the computational model, where messages are bitstrings and adversaries are probabilistic algorithms. A complementary, older tradition is the symbolic model, whose canonical adversary is the Dolev-Yao attacker (Dolev and Yao, 1983). In the Dolev-Yao model the network is the adversary: it carries every message and can read, intercept, drop, reorder, replay, and inject messages, and it can apply cryptographic operations it has the keys for, but the cryptography itself is treated as a perfect “black box” (it cannot break encryption, only use what it legitimately obtains). This abstraction makes protocol logic mechanically analyzable and is the assumption baked into protocol design and into the rules of engagement for network attackers throughout Part III.
Because the symbolic model is mechanizable, it powers a family of formal-verification tools that have found real flaws in deployed protocols:
ProVerif verifies cryptographic protocols in the symbolic (Dolev-Yao) model using the applied pi calculus and Horn-clause resolution, proving secrecy and authentication for an unbounded number of sessions.
Tamarin Prover is a symbolic tool using multiset rewriting and backward reasoning for unbounded sessions; it has been used to verify 5G authenticated key agreement, TLS 1.3, and the EMV payment standard.
EasyCrypt works instead in the computational model, mechanizing game-based proofs by reasoning about relational properties of probabilistic programs with adversarial code, so that reduction proofs can be checked by machine rather than trusted by eye.
Symbolic tools give strong automation and broad coverage at the cost of the perfect-cryptography abstraction; computational tools like EasyCrypt give proofs closer to reality at the cost of much greater effort. Mature analyses increasingly use both.
flowchart LR
subgraph SYM[Symbolic model]
DY[Dolev-Yao adversary<br/>controls the network] --> PV[ProVerif / Tamarin<br/>automated, unbounded sessions]
end
subgraph COMP[Computational model]
PPT[PPT adversary<br/>bitstrings + probability] --> EC[EasyCrypt<br/>machine-checked game proofs]
end
PV -.->|find flaws / prove logic| GOAL[Protocol assurance]
EC -.->|reduction to hard problems| GOAL
A Taxonomy of Security Properties#
A security analysis is only as clear as the property it claims, so it helps to name the properties precisely. The triad of Chapter 1 (confidentiality, integrity, availability) is the foundation, but cryptographic protocols target a richer set, and privacy-preserving machine learning adds two more.
Confidentiality: the data is unreadable to unauthorized parties (the IND notions).
Integrity: unauthorized modification is detectable (MACs, hashes, signatures).
Authentication: the claimed identity of a party or origin of a message is verified.
Authorization: an authenticated party may perform only permitted actions (access control).
Authenticity: a message genuinely originates from its claimed source (integrity plus origin authentication, as AEAD provides).
Non-repudiation: a party cannot later deny an action, provided by digital signatures and audit logs.
Availability: authorized access is preserved despite attack (denial-of-service resistance).
Auditability: actions are recorded so they can be reviewed and attributed after the fact.
Forward secrecy: compromise of a long-term key does not expose past session keys, achieved with ephemeral Diffie-Hellman so each session has an independent, discarded key.
Replay resistance: a captured valid message cannot be re-used, via nonces, sequence numbers, or timestamps (recall AEAD alone does not provide this, Section 2.8).
Unlinkability: an observer cannot tell whether two actions or messages came from the same entity.
Anonymity: an entity’s identity is hidden within a set of possible actors (the anonymity set).
Two properties are specific to collaborative machine learning and recur in Chapter 17. Resistance to model poisoning means malicious training updates cannot corrupt the global model (defended with Byzantine-robust aggregation, often over encrypted updates). Resistance to membership inference means an adversary cannot determine whether a particular record was in the training set (defended with differential privacy and encryption). Differential privacy provides a formal privacy guarantee, an (epsilon, delta) bound on how much any single record can change the output distribution, and is the rigorous backbone of modern privacy-preserving ML and differential-privacy systems.
Writing a Security Analysis: Proof Sketches and Experimental Evaluation#
Putting the pieces together, a complete security analysis, of the kind found in the papers cited in Appendix E, typically contains a recognizable set of components, and knowing the template makes both reading and writing them far easier:
a threat model naming the asset, the adversary model and its oracle access, the security goal, and the assumptions;
an explicit adversary definition and a security-property claim drawn from the taxonomy above;
one or more theorems with proof sketches (a reduction: “if an adversary breaks the scheme with non-negligible advantage, we build an algorithm that solves DDH / forges in EUF-CMA / distinguishes in the simulation”, made rigorous by a sequence of game hops);
where relevant, a formal-verification result (ProVerif/Tamarin in the symbolic model, EasyCrypt in the computational model); and
an experimental security evaluation measuring real-world behavior, attack-success rates under implemented attacks, overhead, and, increasingly, cryptographic benchmarking of competing schemes on common datasets and hardware.
This template is the connective tissue between the theory of this chapter and the applied research of Chapter 17: SigML and SplitML, for instance, pair IND-CPA^D and (epsilon, delta)-DP guarantees with measured membership-inference resistance and performance benchmarks, exactly the blend of formal claim and experimental validation described here.
Knowledge Check
What does provable (reductionist) security actually establish, and against what is the scheme reduced?
Distinguish DDH from CDH, and name a scheme whose IND-CPA security is equivalent to DDH.
What additional guarantee does UC security give over plain game-based or stand-alone simulation security?
Contrast the adversary in the Dolev-Yao (symbolic) model with the PPT adversary of the computational model.
Answers: (1) It reduces breaking the scheme to solving a problem assumed hard, so any efficient break would also solve that problem; security is therefore conditional on the assumption. (2) CDH is computing g^{ab}; DDH is distinguishing g^{ab} from random (strictly stronger); ElGamal is IND-CPA secure iff DDH holds. (3) Security under arbitrary concurrent composition with other protocols (the UC composition theorem), not just in isolation. (4) Dolev-Yao controls the network (read/drop/reorder/replay/inject) but treats crypto as a perfect black box; the computational adversary manipulates bitstrings with bounded probabilistic computation and may break crypto with some (negligible-target) probability.
2.21 Post-Quantum Standards and the Migration Timeline#
Section 2.15 introduced the threat that a large quantum computer poses to RSA and elliptic-curve cryptography, whose security rests on integer factoring and discrete logarithms that Shor’s algorithm would solve efficiently. In August 2024, after an eight-year public competition that began in 2016, NIST published the first finalized post-quantum standards, which name specific algorithms that systems should migrate to:
FIPS 203, ML-KEM (Module-Lattice-Based Key-Encapsulation Mechanism, derived from CRYSTALS-Kyber), for establishing shared keys.
FIPS 204, ML-DSA (Module-Lattice-Based Digital Signature Algorithm, derived from CRYSTALS-Dilithium), for digital signatures.
FIPS 205, SLH-DSA (Stateless Hash-Based Digital Signature Algorithm, derived from SPHINCS+), a signature scheme whose security rests only on hash functions, providing a conservative alternative to the lattice-based signatures.
To avoid depending on a single mathematical family, NIST selected an additional key-encapsulation mechanism, HQC, on March 11, 2025, based on error-correcting codes rather than lattices, with its draft standard to follow.
The migration has a published timeline. NIST IR 8547 (initial public draft, 2024) calls for deprecating RSA and elliptic-curve cryptography for federal use after 2030 and disallowing them entirely, including for legacy interoperability, after 2035. For US national security systems, the NSA Commercial National Security Algorithm Suite (CNSA) 2.0 sets its own schedule and specifies the strongest parameter sets, ML-KEM-1024 and ML-DSA-87. The practical advice for builders today is to inventory where public-key cryptography is used, prefer crypto-agile designs that can swap algorithms, and adopt hybrid schemes that run a classical and a post-quantum algorithm together during the transition. The urgency comes from harvest-now-decrypt-later attacks, in which an adversary records encrypted traffic today to decrypt once a quantum computer exists, so data that must stay confidential for many years is already at risk.
Worked Example: Toy Ring-LWE Encryption#
The toy LWE demo earlier in this chapter used plain vectors. Real lattice schemes such as ML-KEM work over polynomial rings for efficiency. The cell below is a minimal Ring-LWE public-key encryption of a single bit in the ring Z_q[x]/(x^n + 1). It is for intuition only, not security: parameters are tiny and there is no padding or constant-time care.
# Toy Ring-LWE public-key encryption of one bit (educational, NOT secure)
import numpy as np
rng = np.random.default_rng(7)
n, q = 16, 12289 # ring degree and modulus
def polmul(a, b): # multiply in Z_q[x]/(x^n + 1)
res = np.zeros(2*n - 1, dtype=np.int64)
for i in range(n):
res[i:i+n] += a[i] * b
out = res[:n].copy()
out[:n-1] -= res[n:2*n-1] # x^n = -1
return out % q
small = lambda: rng.integers(-1, 2, size=n) # coefficients in {-1,0,1}
# key generation
s = small() # secret
a = rng.integers(0, q, size=n) # public random
b = (polmul(a, s) + small()) % q # public: b = a*s + e
def encrypt(m): # m in {0,1}
r, e1, e2 = small(), small(), small()
u = (polmul(a, r) + e1) % q
v = (polmul(b, r) + e2 + m*(q//2)) % q
return u, v
def decrypt(u, v):
d = (v - polmul(u, s)) % q
dc = ((d + q//2) % q) - q//2 # center coefficients in (-q/2, q/2]
return 1 if abs(int(dc[0])) > q//4 else 0
for m in (0, 1):
u, v = encrypt(m)
print(f"plaintext bit {m} -> decrypted {decrypt(u, v)}")
Chapter Summary#
This chapter built cryptography from its goals to its guarantees. It opened with what cryptography promises and why classical ciphers fall, then established perfect secrecy and the one-time pad and distinguished true, pseudo, and cryptographically secure randomness. It covered symmetric encryption with stream and block ciphers and their modes of operation, cryptographic hash functions, message authentication codes and authenticated encryption, and key derivation for password storage. On the asymmetric side it developed public-key cryptography and RSA, Diffie-Hellman key exchange, elliptic-curve cryptography, and digital signatures, certificates, and PKI, tying them together in the TLS handshake. It closed with advanced and emerging cryptography, key management, a taxonomy of cryptographic attacks, applied cryptographic systems, guidance for protecting data at rest, in transit, and in use, tamper-evident mechanisms, and a treatment of formal, provable security. The recurring lesson is to rely on standard, well-analyzed primitives used correctly rather than on secrecy of design.
Why This Matters#
Cryptography is the load-bearing wall of digital security. Every other chapter leans on it: secure networking is TLS, secure authentication stores password hashes and verifies signatures, blockchains are hash chains and signatures, and privacy engineering increasingly relies on the advanced primitives in Section 2.15. Just as important is knowing cryptography’s failure modes, weak randomness, key and nonce reuse, broken hashes, missing authentication, padding oracles, downgrade attacks, because in practice systems are almost never broken by defeating AES or RSA head-on; they are broken at the seams, where the mathematics meets fallible engineering. A practitioner who understands both the guarantees and their preconditions can choose, configure, and audit cryptographic systems correctly, which is exactly what certifications from Security+ through CISSP test, and what real adversaries probe.
With the mathematical foundations of security in place, the next chapter turns to the networks over which all of this cryptography travels: how data moves, how the protocols work, and how both are attacked and defended.
News in Focus: Heartbleed (2014)#
In April 2014, researchers disclosed Heartbleed, a vulnerability in the widely used OpenSSL library (tracked as CVE-2014-0160). The flaw was not in any cryptographic algorithm but in a memory-handling bug in OpenSSL’s implementation of the TLS heartbeat extension: a missing bounds check let an attacker request more data than they had supplied, causing the server to return up to 64 kilobytes of adjacent memory per request. That memory could contain private keys, session cookies, usernames, and passwords, and the attack left no trace in normal logs.
Through this chapter’s lens, Heartbleed is a textbook example of the gap between sound algorithms and fragile implementations. TLS, RSA, and the ciphers involved were all secure; the breach came from a buffer over-read in C code, the kind of memory-safety failure examined in the exploitation chapter. The response illustrates cryptographic operations under stress: affected organizations had to patch OpenSSL, revoke and reissue TLS certificates because private keys might have leaked, and force password resets at scale, exactly the PKI revocation machinery described in Section 2.13. The episode also accelerated interest in memory-safe languages and in funding for critical open-source infrastructure. These details reflect public reporting from the time and may be refined by later analysis.
Review Questions (MCQ)#
Q1. Kerckhoffs’s principle states that a cryptosystem should be secure even if: A. The key is short B. Everything except the key is public C. The algorithm is secret D. No one attacks it
Q2. The one-time pad achieves perfect secrecy only if the key is: A. 128 bits B. Reused for efficiency C. Truly random, secret, and as long as the message D. A strong password
Q3. Why is ECB mode insecure for most data? A. It is too slow B. Identical plaintext blocks yield identical ciphertext blocks C. It needs no key D. It cannot decrypt
Q4. Which generator is safe for cryptographic keys?
A. A linear congruential generator B. Python’s default random C. The Mersenne Twister D. A CSPRNG such as secrets/os.urandom
Q5. The birthday paradox implies that finding a collision in an n-bit hash takes about: A. 2^n work B. 2^(n/2) work C. n work D. n^2 work
Q6. HMAC is preferred over hash(key || message) because the latter is vulnerable to:
A. Brute force B. Length-extension attacks C. Birthday attacks D. Padding oracles
Q7. AES-GCM provides, beyond confidentiality: A. Nothing extra B. Compression C. Integrity and authentication (AEAD) D. Key exchange
Q8. RSA’s security primarily rests on the hardness of: A. Discrete logarithms B. Factoring large integers C. The elliptic-curve discrete log D. Hashing
Q9. Forward secrecy ensures that: A. Keys never expire B. Past sessions stay secret even if the long-term key is later stolen C. The future is encrypted D. Certificates never need revocation
Q10. A 256-bit elliptic-curve key offers security roughly comparable to an RSA key of: A. 256 bits B. 512 bits C. 1024 bits D. 3072 bits
Q11. Which property is unique to digital signatures (versus a MAC)? A. Integrity B. Authentication C. Non-repudiation D. Confidentiality
Q12. For storing user passwords, the best practice is: A. Plain SHA-256 B. Reversible encryption C. A salted, memory-hard KDF such as Argon2id D. Base64 encoding
Q13. In a TLS 1.3 handshake, the shared session keys are derived using: A. ECB B. (EC)DHE key exchange fed into HKDF C. The server password D. MD5
Q14. Shor’s algorithm, on a large quantum computer, would break: A. AES-256 B. SHA-3 C. RSA and elliptic-curve cryptography D. Argon2
Q15. Steganography differs from encryption in that it: A. Uses larger keys B. Hides the existence of the message rather than its content C. Is always unbreakable D. Requires a certificate authority
Q16. Reusing a nonce with the same key in AES-GCM can: A. Improve speed safely B. Leak plaintext relationships and enable forgeries C. Strengthen the key D. Do nothing
Answer Key#
1: B 2: C 3: B 4: D 5: B 6: B 7: C 8: B 9: B 10: D 11: C 12: C 13: B 14: C 15: B 16: B
Q17. In ElGamal encryption, reusing the ephemeral value k for two messages is dangerous because it: A. Speeds up decryption B. Leaks the relationship between the two plaintexts C. Changes the public key D. Has no effect
Q18. ElGamal encryption is probabilistic because: A. The key is random B. A fresh random k makes each encryption of the same message differ C. It uses a hash D. The prime changes
Q17: B Q18: B
Lab Assignment#
Lab 2.1 (beginner) - Break a cipher. Use the Section 2.2 code to brute-force the Caesar challenge strings, then take a longer monoalphabetic ciphertext and break it with frequency analysis. Write a short explanation of which language features made the break possible.
Lab 2.2 (beginner/intermediate) - Randomness matters. Generate 1000 values from the toy LCG and from
secrets. Plot histograms and successive-pair scatter plots of each. Identify visible structure in the
LCG output and explain why it disqualifies the LCG for key generation.
Lab 2.3 (intermediate) - Modes and integrity. Encrypt the same image in ECB and CBC using the Section 2.6 code and compare. Then flip one byte of a CBC ciphertext, decrypt, and observe the result; repeat with AES-GCM and show that decryption fails (tamper detected). Explain the difference.
Lab 2.4 (intermediate) - Password cracking economics. Hash a small list of weak passwords with plain SHA-256 and time how many guesses per second you can check; then do the same with PBKDF2 at 200,000 iterations and with Argon2id. Estimate how key stretching changes an attacker’s cost per cracked password.
Lab 2.5 (advanced/research) - Build a mini-PKI and a homomorphic tally. (a) Create a self-signed root CA, issue a server certificate, and validate the chain with a library. (b) Implement an additively homomorphic voting tally using the Paillier cryptosystem (via a library): encrypt individual votes, combine the ciphertexts (in Paillier, by multiplying them modulo n^2, which adds the plaintext votes), and decrypt only the total, confirming individual votes are never revealed. Discuss the threat model and what the scheme does and does not protect.
Lab 2.6 (intermediate) - Inspect a real TLS handshake in Wireshark. Capture traffic while visiting an
HTTPS site, then filter for tls (or ssl). Locate the ClientHello and ServerHello and answer: which TLS
version is negotiated (note the version constant, for example 0x0303 for TLS 1.2 or the TLS 1.3 supported-
versions extension); how many random bytes appear in each hello; the session ID length; and the chosen
cipher suite (name and value). Identify who sends the Certificate and who sends the Change Cipher Spec.
Then visit a site still offering an older configuration and compare the negotiated cipher suite, explaining
why a suite such as TLS_RSA_WITH_RC4_128_SHA is now considered weak. Map each observed message to the
handshake described in Section 2.14.
References#
Shannon, C. E. “Communication Theory of Secrecy Systems.” Bell System Technical Journal, 28(4), 1949.
Diffie, W., and Hellman, M. “New Directions in Cryptography.” IEEE Transactions on Information Theory, 22(6), 1976.
Rivest, R., Shamir, A., and Adleman, L. “A Method for Obtaining Digital Signatures and Public-Key Cryptosystems.” Communications of the ACM, 21(2), 1978.
Nakov, S. Practical Cryptography for Developers. https://cryptobook.nakov.com
Boneh, D., and Shoup, V. A Graduate Course in Applied Cryptography. https://crypto.stanford.edu/~dabo/cryptobook/
Katz, J., and Lindell, Y. Introduction to Modern Cryptography, 3rd ed. CRC Press, 2020.
National Institute of Standards and Technology. FIPS 197: Advanced Encryption Standard (AES), 2001.
National Institute of Standards and Technology. FIPS 203 (ML-KEM), FIPS 204 (ML-DSA), FIPS 205 (SLH-DSA): Post-Quantum Cryptography Standards, 2024.
Gentry, C. “Fully Homomorphic Encryption Using Ideal Lattices.” STOC, 2009.
Rescorla, E. The Transport Layer Security (TLS) Protocol Version 1.3. RFC 8446, IETF, 2018.
Vaudenay, S. “Security Flaws Induced by CBC Padding.” EUROCRYPT, 2002.
ElGamal, T. “A Public Key Cryptosystem and a Signature Scheme Based on Discrete Logarithms.” IEEE Transactions on Information Theory, 1985.
Crypto++ Library. ElGamal encryption reference implementation (accompanying source: cryptopp-elgamal.cpp).
Hahn, F., Peter, A., et al. Research on searchable/homomorphic encryption, function secret sharing, and privacy-preserving federated learning (University of Twente). https://research.utwente.nl/en/persons/florian-werner-hahn/
Boneh, D., Sahai, A., and Waters, B. “Functional Encryption: Definitions and Challenges.” TCC, 2011.
Canetti, R., Dwork, C., Naor, M., and Ostrovsky, R. “Deniable Encryption.” CRYPTO, 1997.
Curtmola, R., Garay, J., Kamara, S., and Ostrovsky, R. “Searchable Symmetric Encryption.” CCS, 2006.
AlFardan, N. J., and Paterson, K. G. (2013). Lucky Thirteen: Breaking the TLS and DTLS Record Protocols. IEEE S&P 2013.
Moeller, B., Duong, T., and Kotowicz, K. (2014). This POODLE Bites: Exploiting the SSL 3.0 Fallback. Security Advisory.
Gueron, S., Langley, A., and Lindell, Y. (2019). AES-GCM-SIV: Nonce Misuse-Resistant Authenticated Encryption. RFC 8452, IETF.
Bellare, M., and Namprempre, C. (2000). Authenticated Encryption: Relations among Notions and Analysis of the Generic Composition Paradigm. ASIACRYPT 2000, LNCS 1976.
Bellare, M., Desai, A., Pointcheval, D., and Rogaway, P. (1998). Relations Among Notions of Security for Public-Key Encryption Schemes. CRYPTO 1998, LNCS 1462.
Goldwasser, S., and Micali, S. (1984). Probabilistic Encryption. Journal of Computer and System Sciences, 28(2). (semantic security)
Wikipedia. Ciphertext indistinguishability. https://en.wikipedia.org/wiki/Ciphertext_indistinguishability (accessed 2026).
Huz, D. (2025). Introduction to Cryptography: Perfect Secrecy. DEV Community. https://dev.to/dmytro_huz/introduction-to-cryptography-perfect-secrecy-37aj
Vermeulen, J. (2015). How the ANC Sent Encrypted Messages in the Fight Against Apartheid. MyBroadband. https://mybroadband.co.za/news/security/131822-how-the-anc-sent-encrypted-messages-in-the-fight-against-apartheid.html
IoTeX (2018). Elliptic-curve Cryptography, IoT Security, and Cryptocurrencies. https://medium.com/iotex/elliptic-curve-cryptography-iot-security-and-cryptocurrencies-bb4acb73e387
Li, B., and Micciancio, D. (2021). On the Security of Homomorphic Encryption on Approximate Numbers. EUROCRYPT 2021, LNCS 12696. (introduces IND-CPA^D and KR-D)
Li, B., Micciancio, D., Schultz, M., and Sorrell, J. (2022). Securing Approximate Homomorphic Encryption Using Differential Privacy. CRYPTO 2022, LNCS 13507.
Cheon, J. H., Choe, H., Passelegue, A., Stehle, D., and Suvanto, E. (2024). Attacks Against the IND-CPA^D Security of Exact FHE Schemes. Cryptology ePrint Archive, 2024/127.
Ogilvie, T. (2025). IND-CPA^D and KR-D Security With Reduced Noise from the HintLWE Problem. ASIACRYPT 2025 / Cryptology ePrint Archive, 2025/1618.
OpenFHE. Static Noise Estimation and Noise Flooding for CKKS (CKKS_NOISE_FLOODING.md) and Security Notes for Homomorphic Encryption. openfheorg/openfhe-development ; https://openfhe-development.readthedocs.io/en/latest/sphinx_rsts/intro/security.html
UCSD Crypto. Dynamic Estimation Attack on the IND-CPA^D Security of CKKS. ucsd-crypto/DynamicEstimationAttack
Goldwasser, S., Micali, S., and Rivest, R. L. (1988). A Digital Signature Scheme Secure Against Adaptive Chosen-Message Attacks (GMR; EUF-CMA). SIAM J. Computing 17(2).
Dolev, D., and Yao, A. C. (1983). On the Security of Public Key Protocols. IEEE Transactions on Information Theory 29(2), 198-207.
Bellare, M., and Rogaway, P. (1993). Random Oracles are Practical: A Paradigm for Designing Efficient Protocols. ACM CCS 1993.
Merkle, R. C. (1989) and Damgard, I. (1989). One-way hash functions / A design principle for hash functions. CRYPTO 1989.
Blanchet, B. ProVerif; Meier, S., Schmidt, B., Cremers, C., Basin, D. The Tamarin Prover; Barthe, G. et al. EasyCrypt. (formal protocol/crypto verification tools)
Hamming, R. W. (1950). Error Detecting and Error Correcting Codes. Bell System Technical Journal 29(2).
Confidential Computing Consortium. A Technical Analysis of Confidential Computing (data in use; Intel SGX, AMD SEV TEEs).
Related work by the author (see Appendix E):
Trivedi, D. (2022). Ciphers and Cryptanalysis; (2025) Cryptanalysis of the Vigenere Cipher. (see Appendix E)
Trivedi, D. (2021). Message Integrity; (2014) Security of Cryptographic Hash Functions. (see Appendix E)
Trivedi, D. (2021). Eavesdropping Attack, Cryptanalysis, and Pseudorandomness; (2021) Quantum Cryptography 101. (see Appendix E)
Trivedi, D. (2023). The Future of Cryptography: Performing Computations on Encrypted Data, ISACA Journal; (2026) Which Cipher Is More Secure? (see Appendix E)
Trivedi, D., Boudguiga, A., Kaaniche, N., Triandopoulos, N. (2023). SigML++, Cryptography 7(4); Trivedi, D. (2011) DNA Computing. (see Appendix E)
Companion code: Python-FHEz (Python 3 + Microsoft SEAL 4 toolkit for fully homomorphic encryption) and chiku (polynomial approximation for encrypted computation). See Appendix F.